commit
1776fce6bb
|
|
@ -11,7 +11,7 @@ RZDCY_MODULES := cfg/ hw/arm7/ hw/aica/ hw/holly/ hw/ hw/gdrom/ hw/maple/ \
|
|||
hw/mem/ hw/pvr/ hw/sh4/ hw/sh4/interpr/ hw/sh4/modules/ plugins/ profiler/ oslib/ \
|
||||
hw/extdev/ hw/arm/ hw/naomi/ imgread/ ./ deps/coreio/ deps/zlib/ deps/chdr/ deps/crypto/ \
|
||||
deps/libelf/ deps/chdpsr/ arm_emitter/ rend/ reios/ deps/libpng/ deps/xbrz/ \
|
||||
deps/xxhash/ deps/libzip/ deps/imgui/ archive/ input/ log/
|
||||
deps/libzip/ deps/imgui/ archive/ input/ log/
|
||||
|
||||
ifndef NOT_ARM
|
||||
RZDCY_MODULES += rec-ARM/
|
||||
|
|
@ -137,6 +137,7 @@ ifdef CHD5_LZMA
|
|||
endif
|
||||
|
||||
RZDCY_CFLAGS += -I$(RZDCY_SRC_DIR)/deps/libpng -I$(RZDCY_SRC_DIR)/deps/zlib
|
||||
RZDCY_CFLAGS += -DXXH_INLINE_ALL -I$(RZDCY_SRC_DIR)/deps/xxhash
|
||||
|
||||
RZDCY_CXXFLAGS := $(RZDCY_CFLAGS) -fno-exceptions -fno-rtti -std=gnu++11
|
||||
|
||||
|
|
|
|||
|
|
@ -0,0 +1,24 @@
|
|||
xxHash Library
|
||||
Copyright (c) 2012-2014, Yann Collet
|
||||
All rights reserved.
|
||||
|
||||
Redistribution and use in source and binary forms, with or without modification,
|
||||
are permitted provided that the following conditions are met:
|
||||
|
||||
* Redistributions of source code must retain the above copyright notice, this
|
||||
list of conditions and the following disclaimer.
|
||||
|
||||
* Redistributions in binary form must reproduce the above copyright notice, this
|
||||
list of conditions and the following disclaimer in the documentation and/or
|
||||
other materials provided with the distribution.
|
||||
|
||||
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND
|
||||
ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED
|
||||
WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
|
||||
DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE FOR
|
||||
ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES
|
||||
(INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;
|
||||
LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON
|
||||
ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
|
||||
(INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS
|
||||
SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|
||||
|
|
@ -0,0 +1,356 @@
|
|||
# ################################################################
|
||||
# xxHash Makefile
|
||||
# Copyright (C) Yann Collet 2012-2015
|
||||
#
|
||||
# GPL v2 License
|
||||
#
|
||||
# This program is free software; you can redistribute it and/or modify
|
||||
# it under the terms of the GNU General Public License as published by
|
||||
# the Free Software Foundation; either version 2 of the License, or
|
||||
# (at your option) any later version.
|
||||
#
|
||||
# This program is distributed in the hope that it will be useful,
|
||||
# but WITHOUT ANY WARRANTY; without even the implied warranty of
|
||||
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
|
||||
# GNU General Public License for more details.
|
||||
#
|
||||
# You should have received a copy of the GNU General Public License along
|
||||
# with this program; if not, write to the Free Software Foundation, Inc.,
|
||||
# 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.
|
||||
#
|
||||
# You can contact the author at :
|
||||
# - xxHash source repository : http://code.google.com/p/xxhash/
|
||||
# ################################################################
|
||||
# xxhsum : provides 32/64 bits hash of one or multiple files, or stdin
|
||||
# ################################################################
|
||||
|
||||
# Version numbers
|
||||
LIBVER_MAJOR_SCRIPT:=`sed -n '/define XXH_VERSION_MAJOR/s/.*[[:blank:]]\([0-9][0-9]*\).*/\1/p' < xxhash.h`
|
||||
LIBVER_MINOR_SCRIPT:=`sed -n '/define XXH_VERSION_MINOR/s/.*[[:blank:]]\([0-9][0-9]*\).*/\1/p' < xxhash.h`
|
||||
LIBVER_PATCH_SCRIPT:=`sed -n '/define XXH_VERSION_RELEASE/s/.*[[:blank:]]\([0-9][0-9]*\).*/\1/p' < xxhash.h`
|
||||
LIBVER_MAJOR := $(shell echo $(LIBVER_MAJOR_SCRIPT))
|
||||
LIBVER_MINOR := $(shell echo $(LIBVER_MINOR_SCRIPT))
|
||||
LIBVER_PATCH := $(shell echo $(LIBVER_PATCH_SCRIPT))
|
||||
LIBVER := $(LIBVER_MAJOR).$(LIBVER_MINOR).$(LIBVER_PATCH)
|
||||
|
||||
CFLAGS ?= -O3
|
||||
DEBUGFLAGS+=-Wall -Wextra -Wconversion -Wcast-qual -Wcast-align -Wshadow \
|
||||
-Wstrict-aliasing=1 -Wswitch-enum -Wdeclaration-after-statement \
|
||||
-Wstrict-prototypes -Wundef -Wpointer-arith -Wformat-security \
|
||||
-Wvla -Wformat=2 -Winit-self -Wfloat-equal -Wwrite-strings \
|
||||
-Wredundant-decls -Wstrict-overflow=5
|
||||
CFLAGS += $(DEBUGFLAGS)
|
||||
FLAGS = $(CFLAGS) $(CPPFLAGS) $(MOREFLAGS)
|
||||
XXHSUM_VERSION = $(LIBVER)
|
||||
|
||||
# Define *.exe as extension for Windows systems
|
||||
ifneq (,$(filter Windows%,$(OS)))
|
||||
EXT =.exe
|
||||
else
|
||||
EXT =
|
||||
endif
|
||||
|
||||
# OS X linker doesn't support -soname, and use different extension
|
||||
# see : https://developer.apple.com/library/mac/documentation/DeveloperTools/Conceptual/DynamicLibraries/100-Articles/DynamicLibraryDesignGuidelines.html
|
||||
ifeq ($(shell uname), Darwin)
|
||||
SHARED_EXT = dylib
|
||||
SHARED_EXT_MAJOR = $(LIBVER_MAJOR).$(SHARED_EXT)
|
||||
SHARED_EXT_VER = $(LIBVER).$(SHARED_EXT)
|
||||
SONAME_FLAGS = -install_name $(LIBDIR)/libxxhash.$(SHARED_EXT_MAJOR) -compatibility_version $(LIBVER_MAJOR) -current_version $(LIBVER)
|
||||
else
|
||||
SONAME_FLAGS = -Wl,-soname=libxxhash.$(SHARED_EXT).$(LIBVER_MAJOR)
|
||||
SHARED_EXT = so
|
||||
SHARED_EXT_MAJOR = $(SHARED_EXT).$(LIBVER_MAJOR)
|
||||
SHARED_EXT_VER = $(SHARED_EXT).$(LIBVER)
|
||||
endif
|
||||
|
||||
LIBXXH = libxxhash.$(SHARED_EXT_VER)
|
||||
|
||||
|
||||
.PHONY: default
|
||||
default: ## generate CLI and libraries in release mode (default for `make`)
|
||||
default: DEBUGFLAGS=
|
||||
default: lib xxhsum_and_links
|
||||
|
||||
.PHONY: all
|
||||
all: lib xxhsum xxhsum_inlinedXXH
|
||||
|
||||
xxhsum: xxhash.o xxhsum.o ## generate command line interface (CLI)
|
||||
|
||||
xxhsum32: CFLAGS += -m32 ## generate CLI in 32-bits mode
|
||||
xxhsum32: xxhash.c xxhsum.c
|
||||
$(CC) $(FLAGS) $^ $(LDFLAGS) -o $@$(EXT)
|
||||
|
||||
xxhash.o: xxhash.h xxh3.h
|
||||
|
||||
xxhsum.o: xxhash.h
|
||||
|
||||
.PHONY: xxhsum_and_links
|
||||
xxhsum_and_links: xxhsum xxh32sum xxh64sum
|
||||
|
||||
xxh32sum xxh64sum: xxhsum
|
||||
ln -sf $^ $@
|
||||
|
||||
xxhsum_inlinedXXH: CPPFLAGS += -DXXH_INLINE_ALL
|
||||
xxhsum_inlinedXXH: xxhsum.c
|
||||
$(CC) $(FLAGS) $^ -o $@$(EXT)
|
||||
|
||||
|
||||
# library
|
||||
|
||||
libxxhash.a: ARFLAGS = rcs
|
||||
libxxhash.a: xxhash.o
|
||||
$(AR) $(ARFLAGS) $@ $^
|
||||
|
||||
$(LIBXXH): LDFLAGS += -shared
|
||||
ifeq (,$(filter Windows%,$(OS)))
|
||||
$(LIBXXH): CFLAGS += -fPIC
|
||||
endif
|
||||
$(LIBXXH): xxhash.c
|
||||
$(CC) $(FLAGS) $^ $(LDFLAGS) $(SONAME_FLAGS) -o $@
|
||||
ln -sf $@ libxxhash.$(SHARED_EXT_MAJOR)
|
||||
ln -sf $@ libxxhash.$(SHARED_EXT)
|
||||
|
||||
.PHONY: libxxhash
|
||||
libxxhash: ## generate dynamic xxhash library
|
||||
libxxhash: $(LIBXXH)
|
||||
|
||||
.PHONY: lib
|
||||
lib: ## generate static and dynamic xxhash libraries
|
||||
lib: libxxhash.a libxxhash
|
||||
|
||||
|
||||
# helper targets
|
||||
|
||||
AWK = awk
|
||||
GREP = grep
|
||||
SORT = sort
|
||||
|
||||
.PHONY: list
|
||||
list: ## list all Makefile targets
|
||||
@$(MAKE) -pRrq -f $(lastword $(MAKEFILE_LIST)) : 2>/dev/null | $(AWK) -v RS= -F: '/^# File/,/^# Finished Make data base/ {if ($$1 !~ "^[#.]") {print $$1}}' | $(SORT) | egrep -v -e '^[^[:alnum:]]' -e '^$@$$' | xargs
|
||||
|
||||
.PHONY: help
|
||||
help: ## list documented targets
|
||||
@$(GREP) -E '^[0-9a-zA-Z_-]+:.*?## .*$$' $(MAKEFILE_LIST) | \
|
||||
$(SORT) | \
|
||||
$(AWK) 'BEGIN {FS = ":.*?## "}; {printf "\033[36m%-30s\033[0m %s\n", $$1, $$2}'
|
||||
|
||||
.PHONY: clean
|
||||
clean: ## remove all build artifacts
|
||||
@$(RM) -r *.dSYM # Mac OS-X specific
|
||||
@$(RM) core *.o libxxhash.*
|
||||
@$(RM) xxhsum$(EXT) xxhsum32$(EXT) xxhsum_inlinedXXH$(EXT) xxh32sum xxh64sum
|
||||
@echo cleaning completed
|
||||
|
||||
|
||||
# =================================================
|
||||
# tests
|
||||
# =================================================
|
||||
|
||||
# make check can be run with cross-compiled binaries on emulated environments (qemu user mode)
|
||||
# by setting $(RUN_ENV) to the target emulation environment
|
||||
.PHONY: check
|
||||
check: xxhsum ## basic tests for xxhsum CLI, set RUN_ENV for emulated environments
|
||||
# stdin
|
||||
$(RUN_ENV) ./xxhsum < xxhash.c
|
||||
# multiple files
|
||||
$(RUN_ENV) ./xxhsum xxhash.* xxhsum.*
|
||||
# internal bench
|
||||
$(RUN_ENV) ./xxhsum -bi1
|
||||
# file bench
|
||||
$(RUN_ENV) ./xxhsum -bi1 xxhash.c
|
||||
|
||||
|
||||
.PHONY: test-mem
|
||||
VALGRIND = valgrind --leak-check=yes --error-exitcode=1
|
||||
test-mem: xxhsum ## valgrind tests for xxhsum CLI, looking for memory leaks
|
||||
$(VALGRIND) ./xxhsum -bi1 xxhash.c
|
||||
$(VALGRIND) ./xxhsum -H0 xxhash.c
|
||||
$(VALGRIND) ./xxhsum -H1 xxhash.c
|
||||
|
||||
.PHONY: test32
|
||||
test32: clean xxhsum32
|
||||
@echo ---- test 32-bit ----
|
||||
./xxhsum32 -bi1 xxhash.c
|
||||
|
||||
.PHONY: test-xxhsum-c
|
||||
test-xxhsum-c: xxhsum
|
||||
# xxhsum to/from pipe
|
||||
./xxhsum lib* | ./xxhsum -c -
|
||||
./xxhsum -H0 lib* | ./xxhsum -c -
|
||||
# xxhsum to/from file, shell redirection
|
||||
./xxhsum lib* > .test.xxh64
|
||||
./xxhsum -H0 lib* > .test.xxh32
|
||||
./xxhsum -c .test.xxh64
|
||||
./xxhsum -c .test.xxh32
|
||||
./xxhsum -c < .test.xxh64
|
||||
./xxhsum -c < .test.xxh32
|
||||
# xxhsum -c warns improperly format lines.
|
||||
cat .test.xxh64 .test.xxh32 | ./xxhsum -c -
|
||||
cat .test.xxh32 .test.xxh64 | ./xxhsum -c -
|
||||
# Expects "FAILED"
|
||||
echo "0000000000000000 LICENSE" | ./xxhsum -c -; test $$? -eq 1
|
||||
echo "00000000 LICENSE" | ./xxhsum -c -; test $$? -eq 1
|
||||
# Expects "FAILED open or read"
|
||||
echo "0000000000000000 test-expects-file-not-found" | ./xxhsum -c -; test $$? -eq 1
|
||||
echo "00000000 test-expects-file-not-found" | ./xxhsum -c -; test $$? -eq 1
|
||||
@$(RM) -f .test.xxh32 .test.xxh64
|
||||
|
||||
.PHONY: armtest
|
||||
armtest: clean
|
||||
@echo ---- test ARM compilation ----
|
||||
CC=arm-linux-gnueabi-gcc MOREFLAGS="-Werror -static" $(MAKE) xxhsum
|
||||
|
||||
.PHONY: clangtest
|
||||
clangtest: clean
|
||||
@echo ---- test clang compilation ----
|
||||
CC=clang MOREFLAGS="-Werror -Wconversion -Wno-sign-conversion" $(MAKE) all
|
||||
|
||||
.PHONY: cxxtest
|
||||
cxxtest: clean
|
||||
@echo ---- test C++ compilation ----
|
||||
CC="$(CXX) -Wno-deprecated" $(MAKE) all CFLAGS="-O3 -Wall -Wextra -Wundef -Wshadow -Wcast-align -Werror -fPIC"
|
||||
|
||||
.PHONY: c90test
|
||||
c90test: CPPFLAGS += -DXXH_NO_LONG_LONG
|
||||
c90test: CFLAGS += -std=c90 -Werror -pedantic
|
||||
c90test: xxhash.c
|
||||
@echo ---- test strict C90 compilation [xxh32 only] ----
|
||||
$(RM) xxhash.o
|
||||
$(CC) $(FLAGS) $^ $(LDFLAGS) -c
|
||||
$(RM) xxhash.o
|
||||
|
||||
usan: CC=clang
|
||||
usan: ## check CLI runtime for undefined behavior, using clang's sanitizer
|
||||
@echo ---- check undefined behavior - sanitize ----
|
||||
$(MAKE) clean
|
||||
$(MAKE) test CC=$(CC) MOREFLAGS="-g -fsanitize=undefined -fno-sanitize-recover=all"
|
||||
|
||||
.PHONY: staticAnalyze
|
||||
SCANBUILD ?= scan-build
|
||||
staticAnalyze: clean ## check C source files using $(SCANBUILD) static analyzer
|
||||
@echo ---- static analyzer - $(SCANBUILD) ----
|
||||
CFLAGS="-g -Werror" $(SCANBUILD) --status-bugs -v $(MAKE) all
|
||||
|
||||
CPPCHECK ?= cppcheck
|
||||
.PHONY: cppcheck
|
||||
cppcheck: ## check C source files using $(CPPCHECK) static analyzer
|
||||
@echo ---- static analyzer - $(CPPCHECK) ----
|
||||
$(CPPCHECK) . --force --enable=warning,portability,performance,style --error-exitcode=1 > /dev/null
|
||||
|
||||
.PHONY: namespaceTest
|
||||
namespaceTest: ## ensure XXH_NAMESPACE redefines all public symbols
|
||||
$(CC) -c xxhash.c
|
||||
$(CC) -DXXH_NAMESPACE=TEST_ -c xxhash.c -o xxhash2.o
|
||||
$(CC) xxhash.o xxhash2.o xxhsum.c -o xxhsum2 # will fail if one namespace missing (symbol collision)
|
||||
$(RM) *.o xxhsum2 # clean
|
||||
|
||||
MD2ROFF ?= ronn
|
||||
MD2ROFF_FLAGS ?= --roff --warnings --manual="User Commands" --organization="xxhsum $(XXHSUM_VERSION)"
|
||||
xxhsum.1: xxhsum.1.md
|
||||
cat $^ | $(MD2ROFF) $(MD2ROFF_FLAGS) | sed -n '/^\.\\\".*/!p' > $@
|
||||
|
||||
.PHONY: man
|
||||
man: xxhsum.1 ## generate man page from markdown source
|
||||
|
||||
.PHONY: clean-man
|
||||
clean-man:
|
||||
$(RM) xxhsum.1
|
||||
|
||||
.PHONY: preview-man
|
||||
preview-man: man
|
||||
man ./xxhsum.1
|
||||
|
||||
.PHONY: test
|
||||
test: DEBUGFLAGS += -DDEBUGLEVEL=1
|
||||
test: all namespaceTest check test-xxhsum-c c90test
|
||||
|
||||
.PHONY: test-all
|
||||
test-all: CFLAGS += -Werror
|
||||
test-all: test test32 clangtest cxxtest usan listL120 trailingWhitespace staticAnalyze
|
||||
|
||||
.PHONY: listL120
|
||||
listL120: # extract lines >= 120 characters in *.{c,h}, by Takayuki Matsuoka (note : $$, for Makefile compatibility)
|
||||
find . -type f -name '*.c' -o -name '*.h' | while read -r filename; do awk 'length > 120 {print FILENAME "(" FNR "): " $$0}' $$filename; done
|
||||
|
||||
.PHONY: trailingWhitespace
|
||||
trailingWhitespace:
|
||||
! $(GREP) -E "`printf '[ \\t]$$'`" xxhsum.1 *.c *.h LICENSE Makefile cmake_unofficial/CMakeLists.txt
|
||||
|
||||
|
||||
# =========================================================
|
||||
# make install is validated only for the following targets
|
||||
# =========================================================
|
||||
ifneq (,$(filter $(shell uname),Linux Darwin GNU/kFreeBSD GNU OpenBSD FreeBSD NetBSD DragonFly SunOS))
|
||||
|
||||
DESTDIR ?=
|
||||
# directory variables : GNU conventions prefer lowercase
|
||||
# see https://www.gnu.org/prep/standards/html_node/Makefile-Conventions.html
|
||||
# support both lower and uppercase (BSD), use uppercase in script
|
||||
prefix ?= /usr/local
|
||||
PREFIX ?= $(prefix)
|
||||
exec_prefix ?= $(PREFIX)
|
||||
libdir ?= $(exec_prefix)/lib
|
||||
LIBDIR ?= $(libdir)
|
||||
includedir ?= $(PREFIX)/include
|
||||
INCLUDEDIR ?= $(includedir)
|
||||
bindir ?= $(exec_prefix)/bin
|
||||
BINDIR ?= $(bindir)
|
||||
datarootdir ?= $(PREFIX)/share
|
||||
mandir ?= $(datarootdir)/man
|
||||
man1dir ?= $(mandir)/man1
|
||||
|
||||
ifneq (,$(filter $(shell uname),OpenBSD FreeBSD NetBSD DragonFly SunOS))
|
||||
MANDIR ?= $(PREFIX)/man/man1
|
||||
else
|
||||
MANDIR ?= $(man1dir)
|
||||
endif
|
||||
|
||||
ifneq (,$(filter $(shell uname),SunOS))
|
||||
INSTALL ?= ginstall
|
||||
else
|
||||
INSTALL ?= install
|
||||
endif
|
||||
|
||||
INSTALL_PROGRAM ?= $(INSTALL)
|
||||
INSTALL_DATA ?= $(INSTALL) -m 644
|
||||
|
||||
|
||||
.PHONY: install
|
||||
install: lib xxhsum ## install libraries, CLI, links and man page
|
||||
@echo Installing libxxhash
|
||||
@$(INSTALL) -d -m 755 $(DESTDIR)$(LIBDIR)
|
||||
@$(INSTALL_DATA) libxxhash.a $(DESTDIR)$(LIBDIR)
|
||||
@$(INSTALL_PROGRAM) $(LIBXXH) $(DESTDIR)$(LIBDIR)
|
||||
@ln -sf $(LIBXXH) $(DESTDIR)$(LIBDIR)/libxxhash.$(SHARED_EXT_MAJOR)
|
||||
@ln -sf $(LIBXXH) $(DESTDIR)$(LIBDIR)/libxxhash.$(SHARED_EXT)
|
||||
@$(INSTALL) -d -m 755 $(DESTDIR)$(INCLUDEDIR) # includes
|
||||
@$(INSTALL_DATA) xxhash.h $(DESTDIR)$(INCLUDEDIR)
|
||||
@echo Installing xxhsum
|
||||
@$(INSTALL) -d -m 755 $(DESTDIR)$(BINDIR)/ $(DESTDIR)$(MANDIR)/
|
||||
@$(INSTALL_PROGRAM) xxhsum $(DESTDIR)$(BINDIR)/xxhsum
|
||||
@ln -sf xxhsum $(DESTDIR)$(BINDIR)/xxh32sum
|
||||
@ln -sf xxhsum $(DESTDIR)$(BINDIR)/xxh64sum
|
||||
@echo Installing man pages
|
||||
@$(INSTALL_DATA) xxhsum.1 $(DESTDIR)$(MANDIR)/xxhsum.1
|
||||
@ln -sf xxhsum.1 $(DESTDIR)$(MANDIR)/xxh32sum.1
|
||||
@ln -sf xxhsum.1 $(DESTDIR)$(MANDIR)/xxh64sum.1
|
||||
@echo xxhash installation completed
|
||||
|
||||
.PHONY: uninstall
|
||||
uninstall: ## uninstall libraries, CLI, links and man page
|
||||
@$(RM) $(DESTDIR)$(LIBDIR)/libxxhash.a
|
||||
@$(RM) $(DESTDIR)$(LIBDIR)/libxxhash.$(SHARED_EXT)
|
||||
@$(RM) $(DESTDIR)$(LIBDIR)/libxxhash.$(SHARED_EXT_MAJOR)
|
||||
@$(RM) $(DESTDIR)$(LIBDIR)/$(LIBXXH)
|
||||
@$(RM) $(DESTDIR)$(INCLUDEDIR)/xxhash.h
|
||||
@$(RM) $(DESTDIR)$(BINDIR)/xxh32sum
|
||||
@$(RM) $(DESTDIR)$(BINDIR)/xxh64sum
|
||||
@$(RM) $(DESTDIR)$(BINDIR)/xxhsum
|
||||
@$(RM) $(DESTDIR)$(MANDIR)/xxh32sum.1
|
||||
@$(RM) $(DESTDIR)$(MANDIR)/xxh64sum.1
|
||||
@$(RM) $(DESTDIR)$(MANDIR)/xxhsum.1
|
||||
@echo xxhsum successfully uninstalled
|
||||
|
||||
endif
|
||||
|
|
@ -0,0 +1,192 @@
|
|||
xxHash - Extremely fast hash algorithm
|
||||
======================================
|
||||
|
||||
xxHash is an Extremely fast Hash algorithm, running at RAM speed limits.
|
||||
It successfully completes the [SMHasher](http://code.google.com/p/smhasher/wiki/SMHasher) test suite
|
||||
which evaluates collision, dispersion and randomness qualities of hash functions.
|
||||
Code is highly portable, and hashes are identical on all platforms (little / big endian).
|
||||
|
||||
|Branch |Status |
|
||||
|------------|---------|
|
||||
|master | [](https://travis-ci.org/Cyan4973/xxHash?branch=master) |
|
||||
|dev | [](https://travis-ci.org/Cyan4973/xxHash?branch=dev) |
|
||||
|
||||
|
||||
|
||||
Benchmarks
|
||||
-------------------------
|
||||
|
||||
The benchmark uses SMHasher speed test, compiled with Visual 2010 on a Windows Seven 32-bit box.
|
||||
The reference system uses a Core 2 Duo @3GHz
|
||||
|
||||
|
||||
| Name | Speed | Quality | Author |
|
||||
|---------------|----------|:-------:|------------------|
|
||||
| [xxHash] | 5.4 GB/s | 10 | Y.C. |
|
||||
| MurmurHash 3a | 2.7 GB/s | 10 | Austin Appleby |
|
||||
| SBox | 1.4 GB/s | 9 | Bret Mulvey |
|
||||
| Lookup3 | 1.2 GB/s | 9 | Bob Jenkins |
|
||||
| CityHash64 | 1.05 GB/s| 10 | Pike & Alakuijala|
|
||||
| FNV | 0.55 GB/s| 5 | Fowler, Noll, Vo |
|
||||
| CRC32 | 0.43 GB/s| 9 | |
|
||||
| MD5-32 | 0.33 GB/s| 10 | Ronald L.Rivest |
|
||||
| SHA1-32 | 0.28 GB/s| 10 | |
|
||||
|
||||
[xxHash]: http://www.xxhash.com
|
||||
|
||||
Q.Score is a measure of quality of the hash function.
|
||||
It depends on successfully passing SMHasher test set.
|
||||
10 is a perfect score.
|
||||
Algorithms with a score < 5 are not listed on this table.
|
||||
|
||||
A more recent version, XXH64, has been created thanks to [Mathias Westerdahl](https://github.com/JCash),
|
||||
which offers superior speed and dispersion for 64-bit systems.
|
||||
Note however that 32-bit applications will still run faster using the 32-bit version.
|
||||
|
||||
SMHasher speed test, compiled using GCC 4.8.2, on Linux Mint 64-bit.
|
||||
The reference system uses a Core i5-3340M @2.7GHz
|
||||
|
||||
| Version | Speed on 64-bit | Speed on 32-bit |
|
||||
|------------|------------------|------------------|
|
||||
| XXH64 | 13.8 GB/s | 1.9 GB/s |
|
||||
| XXH32 | 6.8 GB/s | 6.0 GB/s |
|
||||
|
||||
This project also includes a command line utility, named `xxhsum`, offering similar features as `md5sum`,
|
||||
thanks to [Takayuki Matsuoka](https://github.com/t-mat) contributions.
|
||||
|
||||
|
||||
### License
|
||||
|
||||
The library files `xxhash.c` and `xxhash.h` are BSD licensed.
|
||||
The utility `xxhsum` is GPL licensed.
|
||||
|
||||
|
||||
### Build modifiers
|
||||
|
||||
The following macros can be set at compilation time,
|
||||
they modify libxxhash behavior. They are all disabled by default.
|
||||
|
||||
- `XXH_INLINE_ALL` : Make all functions `inline`, with bodies directly included within `xxhash.h`.
|
||||
Inlining functions is beneficial for speed on small keys.
|
||||
It's _extremely effective_ when key length is expressed as _a compile time constant_,
|
||||
with performance improvements observed in the +200% range .
|
||||
See [this article](https://fastcompression.blogspot.com/2018/03/xxhash-for-small-keys-impressive-power.html) for details.
|
||||
Note: there is no need for an `xxhash.o` object file in this case.
|
||||
- `XXH_REROLL` : reduce size of generated code. Impact on performance vary, depending on platform and algorithm.
|
||||
- `XXH_ACCEPT_NULL_INPUT_POINTER` : if set to `1`, when input is a `NULL` pointer,
|
||||
xxhash result is the same as a zero-length input
|
||||
(instead of a dereference segfault).
|
||||
Adds one branch at the beginning of the hash.
|
||||
- `XXH_FORCE_MEMORY_ACCESS` : default method `0` uses a portable `memcpy()` notation.
|
||||
Method `1` uses a gcc-specific `packed` attribute, which can provide better performance for some targets.
|
||||
Method `2` forces unaligned reads, which is not standard compliant, but might sometimes be the only way to extract better read performance.
|
||||
- `XXH_CPU_LITTLE_ENDIAN` : by default, endianess is determined at compile time.
|
||||
It's possible to skip auto-detection and force format to little-endian, by setting this macro to 1.
|
||||
Setting it to 0 forces big-endian.
|
||||
- `XXH_PRIVATE_API` : same impact as `XXH_INLINE_ALL`.
|
||||
Name underlines that XXH_* symbols will not be published.
|
||||
- `XXH_NAMESPACE` : prefix all symbols with the value of `XXH_NAMESPACE`.
|
||||
Useful to evade symbol naming collisions,
|
||||
in case of multiple inclusions of xxHash source code.
|
||||
Client applications can still use regular function name,
|
||||
symbols are automatically translated through `xxhash.h`.
|
||||
- `XXH_STATIC_LINKING_ONLY` : gives access to state declaration for static allocation.
|
||||
Incompatible with dynamic linking, due to risks of ABI changes.
|
||||
- `XXH_NO_LONG_LONG` : removes support for XXH64,
|
||||
for targets without 64-bit support.
|
||||
- `XXH_IMPORT` : MSVC specific : should only be defined for dynamic linking, it prevents linkage errors.
|
||||
|
||||
|
||||
### Example
|
||||
|
||||
Calling xxhash 64-bit variant from a C program :
|
||||
|
||||
```C
|
||||
#include "xxhash.h"
|
||||
|
||||
unsigned long long calcul_hash(const void* buffer, size_t length)
|
||||
{
|
||||
unsigned long long const seed = 0; /* or any other value */
|
||||
unsigned long long const hash = XXH64(buffer, length, seed);
|
||||
return hash;
|
||||
}
|
||||
```
|
||||
|
||||
Using streaming variant is more involved, but makes it possible to provide data in multiple rounds :
|
||||
```C
|
||||
#include "stdlib.h" /* abort() */
|
||||
#include "xxhash.h"
|
||||
|
||||
|
||||
unsigned long long calcul_hash_streaming(someCustomType handler)
|
||||
{
|
||||
/* create a hash state */
|
||||
XXH64_state_t* const state = XXH64_createState();
|
||||
if (state==NULL) abort();
|
||||
|
||||
size_t const bufferSize = SOME_SIZE;
|
||||
void* const buffer = malloc(bufferSize);
|
||||
if (buffer==NULL) abort();
|
||||
|
||||
/* Initialize state with selected seed */
|
||||
unsigned long long const seed = 0; /* or any other value */
|
||||
XXH_errorcode const resetResult = XXH64_reset(state, seed);
|
||||
if (resetResult == XXH_ERROR) abort();
|
||||
|
||||
/* Feed the state with input data, any size, any number of times */
|
||||
(...)
|
||||
while ( /* any condition */ ) {
|
||||
size_t const length = get_more_data(buffer, bufferSize, handler);
|
||||
XXH_errorcode const updateResult = XXH64_update(state, buffer, length);
|
||||
if (updateResult == XXH_ERROR) abort();
|
||||
(...)
|
||||
}
|
||||
(...)
|
||||
|
||||
/* Get the hash */
|
||||
XXH64_hash_t const hash = XXH64_digest(state);
|
||||
|
||||
/* State can then be re-used; in this example, it is simply freed */
|
||||
free(buffer);
|
||||
XXH64_freeState(state);
|
||||
|
||||
return (unsigned long long)hash;
|
||||
}
|
||||
```
|
||||
|
||||
### New experimental hash algorithm
|
||||
|
||||
Starting with `v0.7.0`, the library includes a new algorithm, named `XXH3`,
|
||||
able to generate 64 and 128-bits hashes.
|
||||
|
||||
The new algorithm is much faster than its predecessors,
|
||||
for both long and small inputs,
|
||||
as can be observed in following graphs :
|
||||
|
||||
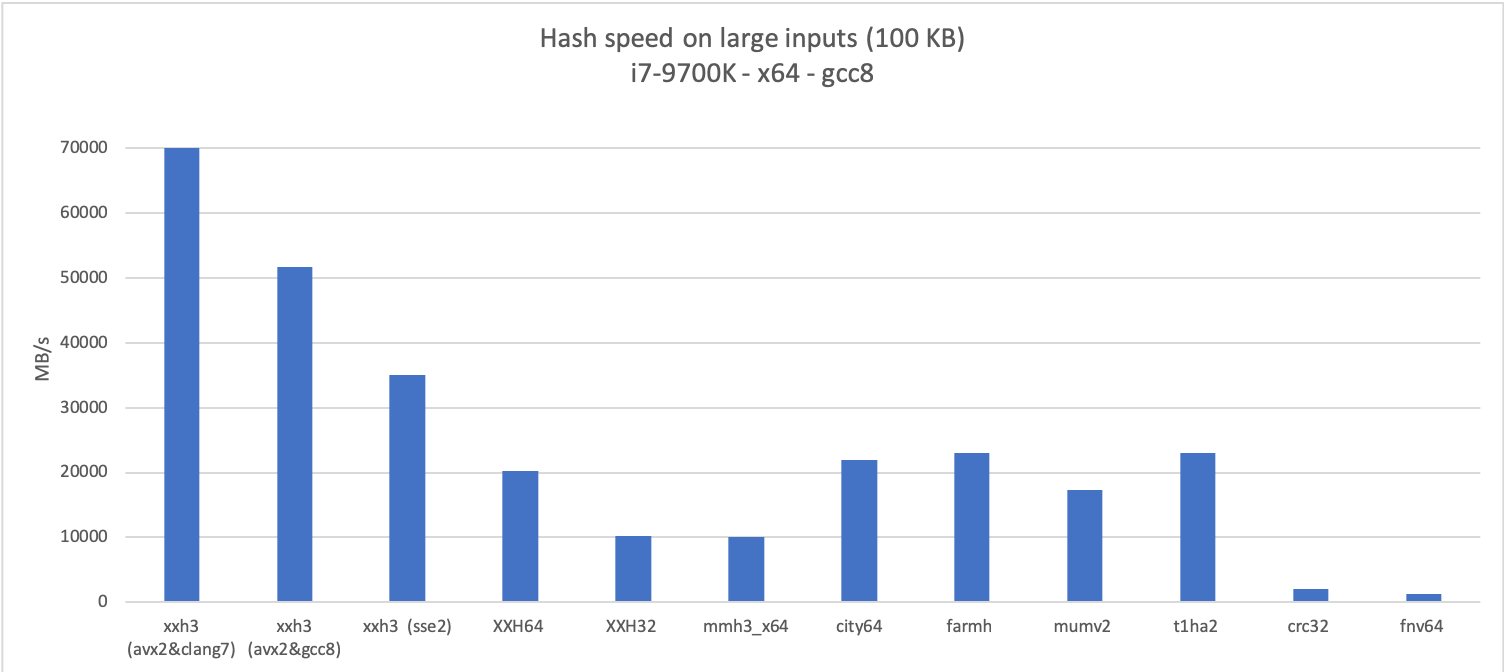
|
||||
|
||||

|
||||
|
||||
The algorithm is currently labelled experimental, its return values can still change in a future version.
|
||||
It can be used for ephemeral data, and for tests, but avoid storing long-term hash values yet.
|
||||
To access it, one need to unlock its declaration using macro `XXH_STATIC_LINKING_ONLY`.
|
||||
`XXH3` will be stabilized in a future version.
|
||||
This period is used to collect users' feedback.
|
||||
|
||||
|
||||
### Other programming languages
|
||||
|
||||
Beyond the C reference version,
|
||||
xxHash is also available on many programming languages,
|
||||
thanks to great contributors.
|
||||
They are [listed here](http://www.xxhash.com/#other-languages).
|
||||
|
||||
|
||||
### Branch Policy
|
||||
|
||||
> - The "master" branch is considered stable, at all times.
|
||||
> - The "dev" branch is the one where all contributions must be merged
|
||||
before being promoted to master.
|
||||
> + If you plan to propose a patch, please commit into the "dev" branch,
|
||||
or its own feature branch.
|
||||
Direct commit to "master" are not permitted.
|
||||
|
|
@ -0,0 +1,108 @@
|
|||
#---------------------------------#
|
||||
# general configuration #
|
||||
#---------------------------------#
|
||||
version: 1.0.{build}
|
||||
max_jobs: 2
|
||||
|
||||
#---------------------------------#
|
||||
# environment configuration #
|
||||
#---------------------------------#
|
||||
clone_depth: 2
|
||||
environment:
|
||||
matrix:
|
||||
- COMPILER: "visual"
|
||||
ARCH: "x64"
|
||||
TEST_XXHSUM: "true"
|
||||
- COMPILER: "visual"
|
||||
ARCH: "x64"
|
||||
APPVEYOR_BUILD_WORKER_IMAGE: Visual Studio 2017
|
||||
TEST_XXHSUM: "true"
|
||||
- COMPILER: "visual"
|
||||
ARCH: "Win32"
|
||||
TEST_XXHSUM: "true"
|
||||
- COMPILER: "visual"
|
||||
ARCH: "Win32"
|
||||
APPVEYOR_BUILD_WORKER_IMAGE: Visual Studio 2013
|
||||
TEST_XXHSUM: "true"
|
||||
- COMPILER: "visual"
|
||||
ARCH: "ARM"
|
||||
- COMPILER: "visual"
|
||||
ARCH: "ARM64"
|
||||
APPVEYOR_BUILD_WORKER_IMAGE: Visual Studio 2017
|
||||
# note : ARM64 is not available with Visual Studio 14 2015, which is default for Appveyor
|
||||
- COMPILER: "gcc"
|
||||
PLATFORM: "mingw64"
|
||||
- COMPILER: "gcc"
|
||||
PLATFORM: "mingw32"
|
||||
- COMPILER: "gcc"
|
||||
PLATFORM: "clang"
|
||||
|
||||
install:
|
||||
- ECHO Installing %COMPILER% %PLATFORM% %ARCH%
|
||||
- MKDIR bin
|
||||
- if [%COMPILER%]==[gcc] SET PATH_ORIGINAL=%PATH%
|
||||
- if [%COMPILER%]==[gcc] (
|
||||
SET "PATH_MINGW32=c:\MinGW\bin;c:\MinGW\usr\bin" &&
|
||||
SET "PATH_MINGW64=c:\msys64\mingw64\bin;c:\msys64\usr\bin" &&
|
||||
COPY C:\MinGW\bin\mingw32-make.exe C:\MinGW\bin\make.exe &&
|
||||
COPY C:\MinGW\bin\gcc.exe C:\MinGW\bin\cc.exe
|
||||
)
|
||||
|
||||
#---------------------------------#
|
||||
# build configuration #
|
||||
#---------------------------------#
|
||||
build_script:
|
||||
- if [%PLATFORM%]==[mingw32] SET PATH=%PATH_MINGW32%;%PATH_ORIGINAL%
|
||||
- if [%PLATFORM%]==[mingw64] SET PATH=%PATH_MINGW64%;%PATH_ORIGINAL%
|
||||
- if [%PLATFORM%]==[clang] SET PATH=%PATH_MINGW64%;%PATH_ORIGINAL%
|
||||
- ECHO ***
|
||||
- ECHO Building %COMPILER% %PLATFORM% %ARCH%
|
||||
- ECHO ***
|
||||
|
||||
- if [%COMPILER%]==[gcc] (
|
||||
if [%PLATFORM%]==[clang] (
|
||||
clang -v
|
||||
) ELSE (
|
||||
gcc -v
|
||||
)
|
||||
)
|
||||
- if [%COMPILER%]==[gcc] (
|
||||
echo ----- &&
|
||||
make -v &&
|
||||
echo ----- &&
|
||||
if not [%PLATFORM%]==[clang] (
|
||||
make -B clean test MOREFLAGS=-Werror
|
||||
) ELSE (
|
||||
make -B clean test CC=clang MOREFLAGS="--target=x86_64-w64-mingw32 -Werror -Wno-pass-failed -Dinline="
|
||||
) &&
|
||||
make -C tests/bench
|
||||
)
|
||||
# note : strict c90 tests with clang fail, due to (erroneous) presence on `inline` keyword in some included system file
|
||||
# -Dinline= is a way to disable this keyword
|
||||
|
||||
- if [%COMPILER%]==[visual] (
|
||||
cd cmake_unofficial &&
|
||||
cmake . -DCMAKE_BUILD_TYPE=Release -A %ARCH% &&
|
||||
cmake --build . --config Release
|
||||
)
|
||||
|
||||
#---------------------------------#
|
||||
# tests configuration #
|
||||
#---------------------------------#
|
||||
test_script:
|
||||
# note : can only run x86 and x64 binaries on Appveyor
|
||||
# note : if %COMPILER%==gcc, xxhsum was already tested within `make test`
|
||||
- if [%TEST_XXHSUM%]==[true] (
|
||||
ECHO *** &&
|
||||
ECHO Testing %COMPILER% %PLATFORM% %ARCH% &&
|
||||
ECHO *** &&
|
||||
cd Release &&
|
||||
xxhsum.exe -bi1 &&
|
||||
ECHO ------- xxhsum tested -------
|
||||
)
|
||||
|
||||
|
||||
#---------------------------------#
|
||||
# artifacts configuration #
|
||||
#---------------------------------#
|
||||
# none yet
|
||||
|
|
@ -0,0 +1,12 @@
|
|||
# cmake artifacts
|
||||
|
||||
CMakeCache.txt
|
||||
CMakeFiles
|
||||
Makefile
|
||||
cmake_install.cmake
|
||||
|
||||
|
||||
# make compilation results
|
||||
|
||||
*.dylib
|
||||
*.a
|
||||
|
|
@ -0,0 +1,168 @@
|
|||
# To the extent possible under law, the author(s) have dedicated all
|
||||
# copyright and related and neighboring rights to this software to
|
||||
# the public domain worldwide. This software is distributed without
|
||||
# any warranty.
|
||||
#
|
||||
# For details, see <http://creativecommons.org/publicdomain/zero/1.0/>.
|
||||
|
||||
cmake_minimum_required (VERSION 2.8.12 FATAL_ERROR)
|
||||
|
||||
set(XXHASH_DIR "${CMAKE_CURRENT_SOURCE_DIR}/..")
|
||||
|
||||
file(STRINGS "${XXHASH_DIR}/xxhash.h" XXHASH_VERSION_MAJOR REGEX "^#define XXH_VERSION_MAJOR +([0-9]+) *$")
|
||||
string(REGEX REPLACE "^#define XXH_VERSION_MAJOR +([0-9]+) *$" "\\1" XXHASH_VERSION_MAJOR "${XXHASH_VERSION_MAJOR}")
|
||||
file(STRINGS "${XXHASH_DIR}/xxhash.h" XXHASH_VERSION_MINOR REGEX "^#define XXH_VERSION_MINOR +([0-9]+) *$")
|
||||
string(REGEX REPLACE "^#define XXH_VERSION_MINOR +([0-9]+) *$" "\\1" XXHASH_VERSION_MINOR "${XXHASH_VERSION_MINOR}")
|
||||
file(STRINGS "${XXHASH_DIR}/xxhash.h" XXHASH_VERSION_RELEASE REGEX "^#define XXH_VERSION_RELEASE +([0-9]+) *$")
|
||||
string(REGEX REPLACE "^#define XXH_VERSION_RELEASE +([0-9]+) *$" "\\1" XXHASH_VERSION_RELEASE "${XXHASH_VERSION_RELEASE}")
|
||||
set(XXHASH_VERSION_STRING "${XXHASH_VERSION_MAJOR}.${XXHASH_VERSION_MINOR}.${XXHASH_VERSION_RELEASE}")
|
||||
set(XXHASH_LIB_VERSION ${XXHASH_VERSION_STRING})
|
||||
set(XXHASH_LIB_SOVERSION "${XXHASH_VERSION_MAJOR}")
|
||||
mark_as_advanced(XXHASH_VERSION_MAJOR XXHASH_VERSION_MINOR XXHASH_VERSION_RELEASE XXHASH_VERSION_STRING XXHASH_LIB_VERSION XXHASH_LIB_SOVERSION)
|
||||
|
||||
if("${CMAKE_VERSION}" VERSION_LESS "3.13")
|
||||
#message(WARNING "CMake ${CMAKE_VERSION} has no CMP0077 policy: options will erase uncached/untyped normal vars!")
|
||||
else()
|
||||
cmake_policy (SET CMP0077 NEW)
|
||||
endif()
|
||||
if("${CMAKE_VERSION}" VERSION_LESS "3.0")
|
||||
project(xxHash C)
|
||||
else()
|
||||
cmake_policy (SET CMP0048 NEW)
|
||||
project(xxHash
|
||||
VERSION ${XXHASH_VERSION_STRING}
|
||||
LANGUAGES C)
|
||||
endif()
|
||||
|
||||
if(NOT CMAKE_BUILD_TYPE AND NOT CMAKE_CONFIGURATION_TYPES)
|
||||
set(CMAKE_BUILD_TYPE "Release" CACHE STRING "Project build type" FORCE)
|
||||
set_property(CACHE CMAKE_BUILD_TYPE
|
||||
PROPERTY STRINGS "Debug" "Release" "RelWithDebInfo" "MinSizeRel")
|
||||
endif()
|
||||
if(NOT CMAKE_CONFIGURATION_TYPES)
|
||||
message(STATUS "xxHash build type: ${CMAKE_BUILD_TYPE}")
|
||||
endif()
|
||||
|
||||
option(BUILD_SHARED_LIBS "Build shared library" ON)
|
||||
set(XXHASH_BUILD_ENABLE_INLINE_API ON CACHE BOOL "add xxhash.c to includes for -DXXH_INLINE_ALL")
|
||||
set(XXHASH_BUILD_XXHSUM ON CACHE BOOL "Build the xxhsum binary")
|
||||
|
||||
# If XXHASH is being bundled in another project, we don't want to
|
||||
# install anything. However, we want to let people override this, so
|
||||
# we'll use the XXHASH_BUNDLED_MODE variable to let them do that; just
|
||||
# set it to OFF in your project before you add_subdirectory(xxhash/cmake_unofficial).
|
||||
if(NOT DEFINED XXHASH_BUNDLED_MODE)
|
||||
if("${PROJECT_SOURCE_DIR}" STREQUAL "${CMAKE_SOURCE_DIR}")
|
||||
set(XXHASH_BUNDLED_MODE OFF)
|
||||
else()
|
||||
set(XXHASH_BUNDLED_MODE ON)
|
||||
endif()
|
||||
endif()
|
||||
set(XXHASH_BUNDLED_MODE ${XXHASH_BUNDLED_MODE} CACHE BOOL "" FORCE)
|
||||
mark_as_advanced(XXHASH_BUNDLED_MODE)
|
||||
|
||||
# Allow people to choose whether to build shared or static libraries
|
||||
# via the BUILD_SHARED_LIBS option unless we are in bundled mode, in
|
||||
# which case we always use static libraries.
|
||||
include(CMakeDependentOption)
|
||||
CMAKE_DEPENDENT_OPTION(BUILD_SHARED_LIBS "Build shared libraries" ON "NOT XXHASH_BUNDLED_MODE" OFF)
|
||||
|
||||
# libxxhash
|
||||
add_library(xxhash "${XXHASH_DIR}/xxhash.c")
|
||||
add_library(${PROJECT_NAME}::xxhash ALIAS xxhash)
|
||||
|
||||
target_include_directories(xxhash
|
||||
PUBLIC
|
||||
$<BUILD_INTERFACE:${XXHASH_DIR}>
|
||||
$<INSTALL_INTERFACE:include/>)
|
||||
if (BUILD_SHARED_LIBS)
|
||||
target_compile_definitions(xxhash PUBLIC XXH_EXPORT)
|
||||
endif ()
|
||||
set_target_properties(xxhash PROPERTIES
|
||||
SOVERSION "${XXHASH_VERSION_STRING}"
|
||||
VERSION "${XXHASH_VERSION_STRING}")
|
||||
|
||||
if(XXHASH_BUILD_XXHSUM)
|
||||
# xxhsum
|
||||
add_executable(xxhsum "${XXHASH_DIR}/xxhsum.c")
|
||||
add_executable(${PROJECT_NAME}::xxhsum ALIAS xxhsum)
|
||||
|
||||
target_link_libraries(xxhsum PRIVATE xxhash)
|
||||
target_include_directories(xxhsum PRIVATE "${XXHASH_DIR}")
|
||||
endif(XXHASH_BUILD_XXHSUM)
|
||||
|
||||
# Extra warning flags
|
||||
include (CheckCCompilerFlag)
|
||||
foreach (flag
|
||||
-Wall -Wextra -Wcast-qual -Wcast-align -Wshadow
|
||||
-Wstrict-aliasing=1 -Wswitch-enum -Wdeclaration-after-statement
|
||||
-Wstrict-prototypes -Wundef)
|
||||
# Because https://gcc.gnu.org/wiki/FAQ#wnowarning
|
||||
string(REGEX REPLACE "\\-Wno\\-(.+)" "-W\\1" flag_to_test "${flag}")
|
||||
string(REGEX REPLACE "[^a-zA-Z0-9]+" "_" test_name "CFLAG_${flag_to_test}")
|
||||
|
||||
check_c_compiler_flag("${ADD_COMPILER_FLAGS_PREPEND} ${flag_to_test}" ${test_name})
|
||||
|
||||
if(${test_name})
|
||||
set(CMAKE_C_FLAGS "${flag} ${CMAKE_C_FLAGS}")
|
||||
endif()
|
||||
|
||||
unset(test_name)
|
||||
unset(flag_to_test)
|
||||
endforeach (flag)
|
||||
|
||||
if(NOT XXHASH_BUNDLED_MODE)
|
||||
include(GNUInstallDirs)
|
||||
|
||||
install(TARGETS xxhash
|
||||
EXPORT xxHashTargets
|
||||
LIBRARY DESTINATION "${CMAKE_INSTALL_LIBDIR}"
|
||||
ARCHIVE DESTINATION "${CMAKE_INSTALL_LIBDIR}")
|
||||
install(FILES "${XXHASH_DIR}/xxhash.h"
|
||||
DESTINATION "${CMAKE_INSTALL_INCLUDEDIR}")
|
||||
if(XXHASH_BUILD_ENABLE_INLINE_API)
|
||||
install(FILES "${XXHASH_DIR}/xxhash.c"
|
||||
DESTINATION "${CMAKE_INSTALL_INCLUDEDIR}")
|
||||
endif()
|
||||
if(XXHASH_BUILD_XXHSUM)
|
||||
install(TARGETS xxhsum
|
||||
EXPORT xxHashTargets
|
||||
RUNTIME DESTINATION "${CMAKE_INSTALL_BINDIR}")
|
||||
install(FILES "${XXHASH_DIR}/xxhsum.1"
|
||||
DESTINATION "${CMAKE_INSTALL_MANDIR}/man1")
|
||||
endif(XXHASH_BUILD_XXHSUM)
|
||||
|
||||
include(CMakePackageConfigHelpers)
|
||||
|
||||
set(xxHash_VERSION_CONFIG "${PROJECT_BINARY_DIR}/xxHashConfigVersion.cmake")
|
||||
set(xxHash_PROJECT_CONFIG "${PROJECT_BINARY_DIR}/xxHashConfig.cmake")
|
||||
set(xxHash_TARGETS_CONFIG "${PROJECT_BINARY_DIR}/xxHashTargets.cmake")
|
||||
set(xxHash_CONFIG_INSTALL_DIR "${CMAKE_INSTALL_LIBDIR}/cmake/xxHash/")
|
||||
write_basic_package_version_file(${xxHash_VERSION_CONFIG}
|
||||
VERSION ${XXHASH_VERSION_STRING}
|
||||
COMPATIBILITY AnyNewerVersion)
|
||||
configure_package_config_file(
|
||||
${PROJECT_SOURCE_DIR}/xxHashConfig.cmake.in
|
||||
${xxHash_PROJECT_CONFIG}
|
||||
INSTALL_DESTINATION ${xxHash_CONFIG_INSTALL_DIR})
|
||||
if("${CMAKE_VERSION}" VERSION_LESS "3.0")
|
||||
set(XXHASH_EXPORT_SET xxhash)
|
||||
if(XXHASH_BUILD_XXHSUM)
|
||||
set(XXHASH_EXPORT_SET ${XXHASH_EXPORT_SET} xxhsum)
|
||||
endif()
|
||||
export(TARGETS ${XXHASH_EXPORT_SET}
|
||||
FILE ${xxHash_TARGETS_CONFIG}
|
||||
NAMESPACE ${PROJECT_NAME}::)
|
||||
else()
|
||||
export(EXPORT xxHashTargets
|
||||
FILE ${xxHash_TARGETS_CONFIG}
|
||||
NAMESPACE ${PROJECT_NAME}::)
|
||||
endif()
|
||||
|
||||
install(FILES ${xxHash_PROJECT_CONFIG} ${xxHash_VERSION_CONFIG}
|
||||
DESTINATION ${xxHash_CONFIG_INSTALL_DIR})
|
||||
install(EXPORT xxHashTargets
|
||||
DESTINATION ${xxHash_CONFIG_INSTALL_DIR}
|
||||
NAMESPACE ${PROJECT_NAME}::)
|
||||
endif(NOT XXHASH_BUNDLED_MODE)
|
||||
|
||||
|
|
@ -0,0 +1,36 @@
|
|||
|
||||
## Usage
|
||||
|
||||
### Way 1: import targets
|
||||
Build xxHash targets:
|
||||
|
||||
cd </path/to/xxHash/>
|
||||
mkdir build
|
||||
cd build
|
||||
cmake ../cmake_unofficial [options]
|
||||
cmake --build .
|
||||
cmake --build . --target install #optional
|
||||
|
||||
Where possible options are:
|
||||
- `-DXXHASH_BUILD_ENABLE_INLINE_API=<ON|OFF>` : adds xxhash.c for the `-DXXH_INLINE_ALL` api. ON by default.
|
||||
- `-DXXHASH_BUILD_XXHSUM=<ON|OFF>` : build the command line binary. ON by default
|
||||
- `-DBUILD_SHARED_LIBS=<ON|OFF>` : build dynamic library. ON by default.
|
||||
- `-DCMAKE_INSTALL_PREFIX=<path>` : use custom install prefix path.
|
||||
|
||||
Add lines into downstream CMakeLists.txt:
|
||||
|
||||
find_package(xxHash 0.7 CONFIG REQUIRED)
|
||||
...
|
||||
target_link_libraries(MyTarget PRIVATE xxHash::xxhash)
|
||||
|
||||
### Way 2: Add subdirectory
|
||||
Add lines into downstream CMakeLists.txt:
|
||||
|
||||
option(BUILD_SHARE_LIBS "Build shared libs" OFF) #optional
|
||||
...
|
||||
set(XXHASH_BUILD_ENABLE_INLINE_API OFF) #optional
|
||||
set(XXHASH_BUILD_XXHSUM OFF) #optional
|
||||
add_subdirectory(</path/to/xxHash/cmake_unofficial/> </path/to/xxHash/build/> EXCLUDE_FROM_ALL)
|
||||
...
|
||||
target_link_libraries(MyTarget PRIVATE xxHash::xxhash)
|
||||
|
||||
|
|
@ -0,0 +1,4 @@
|
|||
@PACKAGE_INIT@
|
||||
|
||||
include(${CMAKE_CURRENT_LIST_DIR}/xxHashTargets.cmake)
|
||||
|
||||
|
|
@ -0,0 +1,9 @@
|
|||
xxHash Specification
|
||||
=======================
|
||||
|
||||
This directory contains material defining the xxHash algorithm.
|
||||
It's described in [this specification document](xxhash_spec.md_).
|
||||
|
||||
The algorithm is also be illustrated by a [simple educational library](https://github.com/easyaspi314/xxhash-clean),
|
||||
written by @easyaspi314 and designed for readability
|
||||
(as opposed to the reference library which is designed for speed).
|
||||
|
|
@ -0,0 +1,316 @@
|
|||
xxHash fast digest algorithm
|
||||
======================
|
||||
|
||||
### Notices
|
||||
|
||||
Copyright (c) Yann Collet
|
||||
|
||||
Permission is granted to copy and distribute this document
|
||||
for any purpose and without charge,
|
||||
including translations into other languages
|
||||
and incorporation into compilations,
|
||||
provided that the copyright notice and this notice are preserved,
|
||||
and that any substantive changes or deletions from the original
|
||||
are clearly marked.
|
||||
Distribution of this document is unlimited.
|
||||
|
||||
### Version
|
||||
|
||||
0.1.1 (10/10/18)
|
||||
|
||||
|
||||
Table of Contents
|
||||
---------------------
|
||||
- [Introduction](#introduction)
|
||||
- [XXH32 algorithm description](#xxh32-algorithm-description)
|
||||
- [XXH64 algorithm description](#xxh64-algorithm-description)
|
||||
- [Performance considerations](#performance-considerations)
|
||||
- [Reference Implementation](#reference-implementation)
|
||||
|
||||
|
||||
Introduction
|
||||
----------------
|
||||
|
||||
This document describes the xxHash digest algorithm, for both 32 and 64 variants, named `XXH32` and `XXH64`. The algorithm takes as input a message of arbitrary length and an optional seed value, it then produces an output of 32 or 64-bit as "fingerprint" or "digest".
|
||||
|
||||
xxHash is primarily designed for speed. It is labelled non-cryptographic, and is not meant to avoid intentional collisions (same digest for 2 different messages), or to prevent producing a message with predefined digest.
|
||||
|
||||
XXH32 is designed to be fast on 32-bits machines.
|
||||
XXH64 is designed to be fast on 64-bits machines.
|
||||
Both variants produce different output.
|
||||
However, a given variant shall produce exactly the same output, irrespective of the cpu / os used. In particular, the result remains identical whatever the endianness and width of the cpu.
|
||||
|
||||
### Operation notations
|
||||
|
||||
All operations are performed modulo {32,64} bits. Arithmetic overflows are expected.
|
||||
`XXH32` uses 32-bit modular operations. `XXH64` uses 64-bit modular operations.
|
||||
|
||||
- `+` : denote modular addition
|
||||
- `*` : denote modular multiplication
|
||||
- `X <<< s` : denote the value obtained by circularly shifting (rotating) `X` left by `s` bit positions.
|
||||
- `X >> s` : denote the value obtained by shifting `X` right by s bit positions. Upper `s` bits become `0`.
|
||||
- `X xor Y` : denote the bit-wise XOR of `X` and `Y` (same width).
|
||||
|
||||
|
||||
XXH32 Algorithm Description
|
||||
-------------------------------------
|
||||
|
||||
### Overview
|
||||
|
||||
We begin by supposing that we have a message of any length `L` as input, and that we wish to find its digest. Here `L` is an arbitrary nonnegative integer; `L` may be zero. The following steps are performed to compute the digest of the message.
|
||||
|
||||
The algorithm collect and transform input in _stripes_ of 16 bytes. The transforms are stored inside 4 "accumulators", each one storing an unsigned 32-bit value. Each accumulator can be processed independently in parallel, speeding up processing for cpu with multiple execution units.
|
||||
|
||||
The algorithm uses 32-bits addition, multiplication, rotate, shift and xor operations. Many operations require some 32-bits prime number constants, all defined below :
|
||||
|
||||
static const u32 PRIME32_1 = 2654435761U; // 0b10011110001101110111100110110001
|
||||
static const u32 PRIME32_2 = 2246822519U; // 0b10000101111010111100101001110111
|
||||
static const u32 PRIME32_3 = 3266489917U; // 0b11000010101100101010111000111101
|
||||
static const u32 PRIME32_4 = 668265263U; // 0b00100111110101001110101100101111
|
||||
static const u32 PRIME32_5 = 374761393U; // 0b00010110010101100110011110110001
|
||||
|
||||
These constants are prime numbers, and feature a good mix of bits 1 and 0, neither too regular, nor too dissymmetric. These properties help dispersion capabilities.
|
||||
|
||||
### Step 1. Initialize internal accumulators
|
||||
|
||||
Each accumulator gets an initial value based on optional `seed` input. Since the `seed` is optional, it can be `0`.
|
||||
|
||||
u32 acc1 = seed + PRIME32_1 + PRIME32_2;
|
||||
u32 acc2 = seed + PRIME32_2;
|
||||
u32 acc3 = seed + 0;
|
||||
u32 acc4 = seed - PRIME32_1;
|
||||
|
||||
#### Special case : input is less than 16 bytes
|
||||
|
||||
When input is too small (< 16 bytes), the algorithm will not process any stripe. Consequently, it will not make use of parallel accumulators.
|
||||
|
||||
In which case, a simplified initialization is performed, using a single accumulator :
|
||||
|
||||
u32 acc = seed + PRIME32_5;
|
||||
|
||||
The algorithm then proceeds directly to step 4.
|
||||
|
||||
### Step 2. Process stripes
|
||||
|
||||
A stripe is a contiguous segment of 16 bytes.
|
||||
It is evenly divided into 4 _lanes_, of 4 bytes each.
|
||||
The first lane is used to update accumulator 1, the second lane is used to update accumulator 2, and so on.
|
||||
|
||||
Each lane read its associated 32-bit value using __little-endian__ convention.
|
||||
|
||||
For each {lane, accumulator}, the update process is called a _round_, and applies the following formula :
|
||||
|
||||
accN = accN + (laneN * PRIME32_2);
|
||||
accN = accN <<< 13;
|
||||
accN = accN * PRIME32_1;
|
||||
|
||||
This shuffles the bits so that any bit from input _lane_ impacts several bits in output _accumulator_. All operations are performed modulo 2^32.
|
||||
|
||||
Input is consumed one full stripe at a time. Step 2 is looped as many times as necessary to consume the whole input, except the last remaining bytes which cannot form a stripe (< 16 bytes).
|
||||
When that happens, move to step 3.
|
||||
|
||||
### Step 3. Accumulator convergence
|
||||
|
||||
All 4 lane accumulators from previous steps are merged to produce a single remaining accumulator of same width (32-bit). The associated formula is as follows :
|
||||
|
||||
acc = (acc1 <<< 1) + (acc2 <<< 7) + (acc3 <<< 12) + (acc4 <<< 18);
|
||||
|
||||
### Step 4. Add input length
|
||||
|
||||
The input total length is presumed known at this stage. This step is just about adding the length to accumulator, so that it participates to final mixing.
|
||||
|
||||
acc = acc + (u32)inputLength;
|
||||
|
||||
Note that, if input length is so large that it requires more than 32-bits, only the lower 32-bits are added to the accumulator.
|
||||
|
||||
### Step 5. Consume remaining input
|
||||
|
||||
There may be up to 15 bytes remaining to consume from the input.
|
||||
The final stage will digest them according to following pseudo-code :
|
||||
|
||||
while (remainingLength >= 4) {
|
||||
lane = read_32bit_little_endian(input_ptr);
|
||||
acc = acc + lane * PRIME32_3;
|
||||
acc = (acc <<< 17) * PRIME32_4;
|
||||
input_ptr += 4; remainingLength -= 4;
|
||||
}
|
||||
|
||||
while (remainingLength >= 1) {
|
||||
lane = read_byte(input_ptr);
|
||||
acc = acc + lane * PRIME32_5;
|
||||
acc = (acc <<< 11) * PRIME32_1;
|
||||
input_ptr += 1; remainingLength -= 1;
|
||||
}
|
||||
|
||||
This process ensures that all input bytes are present in the final mix.
|
||||
|
||||
### Step 6. Final mix (avalanche)
|
||||
|
||||
The final mix ensures that all input bits have a chance to impact any bit in the output digest, resulting in an unbiased distribution. This is also called avalanche effect.
|
||||
|
||||
acc = acc xor (acc >> 15);
|
||||
acc = acc * PRIME32_2;
|
||||
acc = acc xor (acc >> 13);
|
||||
acc = acc * PRIME32_3;
|
||||
acc = acc xor (acc >> 16);
|
||||
|
||||
### Step 7. Output
|
||||
|
||||
The `XXH32()` function produces an unsigned 32-bit value as output.
|
||||
|
||||
For systems which require to store and/or display the result in binary or hexadecimal format, the canonical format is defined to reproduce the same value as the natural decimal format, hence follows __big-endian__ convention (most significant byte first).
|
||||
|
||||
|
||||
XXH64 Algorithm Description
|
||||
-------------------------------------
|
||||
|
||||
### Overview
|
||||
|
||||
`XXH64` algorithm structure is very similar to `XXH32` one. The major difference is that `XXH64` uses 64-bit arithmetic, speeding up memory transfer for 64-bit compliant systems, but also relying on cpu capability to efficiently perform 64-bit operations.
|
||||
|
||||
The algorithm collects and transforms input in _stripes_ of 32 bytes. The transforms are stored inside 4 "accumulators", each one storing an unsigned 64-bit value. Each accumulator can be processed independently in parallel, speeding up processing for cpu with multiple execution units.
|
||||
|
||||
The algorithm uses 64-bit addition, multiplication, rotate, shift and xor operations. Many operations require some 64-bit prime number constants, all defined below :
|
||||
|
||||
static const u64 PRIME64_1 = 11400714785074694791ULL; // 0b1001111000110111011110011011000110000101111010111100101010000111
|
||||
static const u64 PRIME64_2 = 14029467366897019727ULL; // 0b1100001010110010101011100011110100100111110101001110101101001111
|
||||
static const u64 PRIME64_3 = 1609587929392839161ULL; // 0b0001011001010110011001111011000110011110001101110111100111111001
|
||||
static const u64 PRIME64_4 = 9650029242287828579ULL; // 0b1000010111101011110010100111011111000010101100101010111001100011
|
||||
static const u64 PRIME64_5 = 2870177450012600261ULL; // 0b0010011111010100111010110010111100010110010101100110011111000101
|
||||
|
||||
These constants are prime numbers, and feature a good mix of bits 1 and 0, neither too regular, nor too dissymmetric. These properties help dispersion capabilities.
|
||||
|
||||
### Step 1. Initialise internal accumulators
|
||||
|
||||
Each accumulator gets an initial value based on optional `seed` input. Since the `seed` is optional, it can be `0`.
|
||||
|
||||
u64 acc1 = seed + PRIME64_1 + PRIME64_2;
|
||||
u64 acc2 = seed + PRIME64_2;
|
||||
u64 acc3 = seed + 0;
|
||||
u64 acc4 = seed - PRIME64_1;
|
||||
|
||||
#### Special case : input is less than 32 bytes
|
||||
|
||||
When input is too small (< 32 bytes), the algorithm will not process any stripe. Consequently, it will not make use of parallel accumulators.
|
||||
|
||||
In which case, a simplified initialization is performed, using a single accumulator :
|
||||
|
||||
u64 acc = seed + PRIME64_5;
|
||||
|
||||
The algorithm then proceeds directly to step 4.
|
||||
|
||||
### Step 2. Process stripes
|
||||
|
||||
A stripe is a contiguous segment of 32 bytes.
|
||||
It is evenly divided into 4 _lanes_, of 8 bytes each.
|
||||
The first lane is used to update accumulator 1, the second lane is used to update accumulator 2, and so on.
|
||||
|
||||
Each lane read its associated 64-bit value using __little-endian__ convention.
|
||||
|
||||
For each {lane, accumulator}, the update process is called a _round_, and applies the following formula :
|
||||
|
||||
round(accN,laneN):
|
||||
accN = accN + (laneN * PRIME64_2);
|
||||
accN = accN <<< 31;
|
||||
return accN * PRIME64_1;
|
||||
|
||||
This shuffles the bits so that any bit from input _lane_ impacts several bits in output _accumulator_. All operations are performed modulo 2^64.
|
||||
|
||||
Input is consumed one full stripe at a time. Step 2 is looped as many times as necessary to consume the whole input, except the last remaining bytes which cannot form a stripe (< 32 bytes).
|
||||
When that happens, move to step 3.
|
||||
|
||||
### Step 3. Accumulator convergence
|
||||
|
||||
All 4 lane accumulators from previous steps are merged to produce a single remaining accumulator of same width (64-bit). The associated formula is as follows.
|
||||
|
||||
Note that accumulator convergence is more complex than 32-bit variant, and requires to define another function called _mergeAccumulator()_ :
|
||||
|
||||
mergeAccumulator(acc,accN):
|
||||
acc = acc xor round(0, accN);
|
||||
acc = acc * PRIME64_1
|
||||
return acc + PRIME64_4;
|
||||
|
||||
which is then used in the convergence formula :
|
||||
|
||||
acc = (acc1 <<< 1) + (acc2 <<< 7) + (acc3 <<< 12) + (acc4 <<< 18);
|
||||
acc = mergeAccumulator(acc, acc1);
|
||||
acc = mergeAccumulator(acc, acc2);
|
||||
acc = mergeAccumulator(acc, acc3);
|
||||
acc = mergeAccumulator(acc, acc4);
|
||||
|
||||
### Step 4. Add input length
|
||||
|
||||
The input total length is presumed known at this stage. This step is just about adding the length to accumulator, so that it participates to final mixing.
|
||||
|
||||
acc = acc + inputLength;
|
||||
|
||||
### Step 5. Consume remaining input
|
||||
|
||||
There may be up to 31 bytes remaining to consume from the input.
|
||||
The final stage will digest them according to following pseudo-code :
|
||||
|
||||
while (remainingLength >= 8) {
|
||||
lane = read_64bit_little_endian(input_ptr);
|
||||
acc = acc xor round(0, lane);
|
||||
acc = (acc <<< 27) * PRIME64_1;
|
||||
acc = acc + PRIME64_4;
|
||||
input_ptr += 8; remainingLength -= 8;
|
||||
}
|
||||
|
||||
if (remainingLength >= 4) {
|
||||
lane = read_32bit_little_endian(input_ptr);
|
||||
acc = acc xor (lane * PRIME64_1);
|
||||
acc = (acc <<< 23) * PRIME64_2;
|
||||
acc = acc + PRIME64_3;
|
||||
input_ptr += 4; remainingLength -= 4;
|
||||
}
|
||||
|
||||
while (remainingLength >= 1) {
|
||||
lane = read_byte(input_ptr);
|
||||
acc = acc xor (lane * PRIME64_5);
|
||||
acc = (acc <<< 11) * PRIME64_1;
|
||||
input_ptr += 1; remainingLength -= 1;
|
||||
}
|
||||
|
||||
This process ensures that all input bytes are present in the final mix.
|
||||
|
||||
### Step 6. Final mix (avalanche)
|
||||
|
||||
The final mix ensures that all input bits have a chance to impact any bit in the output digest, resulting in an unbiased distribution. This is also called avalanche effect.
|
||||
|
||||
acc = acc xor (acc >> 33);
|
||||
acc = acc * PRIME64_2;
|
||||
acc = acc xor (acc >> 29);
|
||||
acc = acc * PRIME64_3;
|
||||
acc = acc xor (acc >> 32);
|
||||
|
||||
### Step 7. Output
|
||||
|
||||
The `XXH64()` function produces an unsigned 64-bit value as output.
|
||||
|
||||
For systems which require to store and/or display the result in binary or hexadecimal format, the canonical format is defined to reproduce the same value as the natural decimal format, hence follows __big-endian__ convention (most significant byte first).
|
||||
|
||||
Performance considerations
|
||||
----------------------------------
|
||||
|
||||
The xxHash algorithms are simple and compact to implement. They provide a system independent "fingerprint" or digest of a message of arbitrary length.
|
||||
|
||||
The algorithm allows input to be streamed and processed in multiple steps. In such case, an internal buffer is needed to ensure data is presented to the algorithm in full stripes.
|
||||
|
||||
On 64-bit systems, the 64-bit variant `XXH64` is generally faster to compute, so it is a recommended variant, even when only 32-bit are needed.
|
||||
|
||||
On 32-bit systems though, positions are reversed : `XXH64` performance is reduced, due to its usage of 64-bit arithmetic. `XXH32` becomes a faster variant.
|
||||
|
||||
|
||||
Reference Implementation
|
||||
----------------------------------------
|
||||
|
||||
A reference library written in C is available at http://www.xxhash.com .
|
||||
The web page also links to multiple other implementations written in many different languages.
|
||||
It links to the [github project page](https://github.com/Cyan4973/xxHash) where an [issue board](https://github.com/Cyan4973/xxHash/issues) can be used for further public discussions on the topic.
|
||||
|
||||
|
||||
Version changes
|
||||
--------------------
|
||||
v0.1.1 : added a note on rationale for selection of constants
|
||||
v0.1.0 : initial release
|
||||
|
|
@ -0,0 +1 @@
|
|||
-I../..
|
||||
|
|
@ -0,0 +1,11 @@
|
|||
# build artifacts
|
||||
|
||||
*.o
|
||||
benchHash
|
||||
benchHash32
|
||||
benchHash_avx2
|
||||
benchHash_hw
|
||||
|
||||
# test files
|
||||
|
||||
test*
|
||||
|
|
@ -0,0 +1,38 @@
|
|||
|
||||
|
||||
CPPFLAGS += -I../..
|
||||
CFLAGS ?= -O3
|
||||
CFLAGS += -std=c99 -Wall -Wextra -Wstrict-aliasing=1
|
||||
CXXFLAGS ?= -O3
|
||||
|
||||
|
||||
OBJ_LIST = main.o bhDisplay.o benchHash.o benchfn.o timefn.o
|
||||
|
||||
|
||||
default: benchHash
|
||||
|
||||
all: benchHash
|
||||
|
||||
benchHash32: CFLAGS += -m32
|
||||
benchHash32: CXXFLAGS += -m32
|
||||
|
||||
benchHash_avx2: CFLAGS += -mavx2
|
||||
benchHash_avx2: CXXFLAGS += -mavx2
|
||||
|
||||
benchHash_hw: CPPFLAGS += -DHARDWARE_SUPPORT
|
||||
benchHash_hw: CFLAGS += -mavx2 -maes
|
||||
benchHash_hw: CXXFLAGS += -mavx2 -mpclmul -std=c++14
|
||||
|
||||
benchHash benchHash32 benchHash_avx2 benchHash_nosimd benchHash_hw: $(OBJ_LIST)
|
||||
$(CXX) $(CPPFLAGS) $(CXXFLAGS) $^ $(LDFLAGS) -o $@
|
||||
|
||||
|
||||
main.o: bhDisplay.h hashes.h
|
||||
|
||||
bhDisplay.o: bhDisplay.h benchHash.h
|
||||
|
||||
benchHash.o: benchHash.h
|
||||
|
||||
|
||||
clean:
|
||||
$(RM) *.o benchHash benchHash32 benchHash_avx2 benchHash_hw
|
||||
|
|
@ -0,0 +1,172 @@
|
|||
/*
|
||||
* Hash benchmark module
|
||||
* Part of xxHash project
|
||||
* Copyright (C) 2019-present, Yann Collet
|
||||
*
|
||||
* BSD 2-Clause License (http://www.opensource.org/licenses/bsd-license.php)
|
||||
*
|
||||
* Redistribution and use in source and binary forms, with or without
|
||||
* modification, are permitted provided that the following conditions are
|
||||
* met:
|
||||
*
|
||||
* * Redistributions of source code must retain the above copyright
|
||||
* notice, this list of conditions and the following disclaimer.
|
||||
* * Redistributions in binary form must reproduce the above
|
||||
* copyright notice, this list of conditions and the following disclaimer
|
||||
* in the documentation and/or other materials provided with the
|
||||
* distribution.
|
||||
*
|
||||
* THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS
|
||||
* "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT
|
||||
* LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR
|
||||
* A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT
|
||||
* OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL,
|
||||
* SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT
|
||||
* LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE,
|
||||
* DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY
|
||||
* THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
|
||||
* (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
|
||||
* OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|
||||
*
|
||||
* You can contact the author at :
|
||||
* - xxHash homepage: http://www.xxhash.com
|
||||
* - xxHash source repository : https://github.com/Cyan4973/xxHash
|
||||
*/
|
||||
|
||||
/* benchmark hash functions */
|
||||
|
||||
#include <stdlib.h> // malloc
|
||||
#include <assert.h>
|
||||
|
||||
#include "benchHash.h"
|
||||
|
||||
|
||||
static void initBuffer(void* buffer, size_t size)
|
||||
{
|
||||
const unsigned long long k1 = 11400714785074694791ULL; /* 0b1001111000110111011110011011000110000101111010111100101010000111 */
|
||||
const unsigned long long k2 = 14029467366897019727ULL; /* 0b1100001010110010101011100011110100100111110101001110101101001111 */
|
||||
unsigned long long acc = k2;
|
||||
unsigned char* const p = (unsigned char*)buffer;
|
||||
for (size_t s = 0; s < size; s++) {
|
||||
acc *= k1;
|
||||
p[s] = (unsigned char)(acc >> 56);
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
#define MARGIN_FOR_LATENCY 1024
|
||||
#define START_MASK (MARGIN_FOR_LATENCY-1)
|
||||
|
||||
typedef size_t (*sizeFunction_f)(size_t targetSize);
|
||||
|
||||
/* bench_hash_internal() :
|
||||
* benchmark hashfn repeateadly over single input of size `size`
|
||||
* return : nb of hashes per second
|
||||
*/
|
||||
static double
|
||||
bench_hash_internal(BMK_benchFn_t hashfn, void* payload,
|
||||
size_t nbBlocks, sizeFunction_f selectSize, size_t size,
|
||||
unsigned total_time_ms, unsigned iter_time_ms)
|
||||
{
|
||||
BMK_timedFnState_shell shell;
|
||||
BMK_timedFnState_t* const txf = BMK_initStatic_timedFnState(&shell, sizeof(shell), total_time_ms, iter_time_ms);
|
||||
assert(txf != NULL);
|
||||
|
||||
size_t const srcSize = (size_t)size;
|
||||
size_t const srcBufferSize = srcSize + MARGIN_FOR_LATENCY;
|
||||
void* const srcBuffer = malloc(srcBufferSize);
|
||||
assert(srcBuffer != NULL);
|
||||
initBuffer(srcBuffer, srcBufferSize);
|
||||
#define FAKE_DSTSIZE 32
|
||||
size_t const dstSize = FAKE_DSTSIZE;
|
||||
char dstBuffer_static[FAKE_DSTSIZE] = {0};
|
||||
|
||||
#define NB_BLOCKS_MAX 1024
|
||||
const void* srcBuffers[NB_BLOCKS_MAX];
|
||||
size_t srcSizes[NB_BLOCKS_MAX];
|
||||
void* dstBuffers[NB_BLOCKS_MAX];
|
||||
size_t dstCapacities[NB_BLOCKS_MAX];
|
||||
assert(nbBlocks < NB_BLOCKS_MAX);
|
||||
|
||||
assert(size > 0);
|
||||
for (size_t n=0; n < nbBlocks; n++) {
|
||||
srcBuffers[n] = srcBuffer;
|
||||
srcSizes[n] = selectSize(size);
|
||||
dstBuffers[n] = dstBuffer_static;
|
||||
dstCapacities[n] = dstSize;
|
||||
}
|
||||
|
||||
|
||||
BMK_benchParams_t params = {
|
||||
.benchFn = hashfn,
|
||||
.benchPayload = payload,
|
||||
.initFn = NULL,
|
||||
.initPayload = NULL,
|
||||
.errorFn = NULL,
|
||||
.blockCount = nbBlocks,
|
||||
.srcBuffers = srcBuffers,
|
||||
.srcSizes = srcSizes,
|
||||
.dstBuffers = dstBuffers,
|
||||
.dstCapacities = dstCapacities,
|
||||
.blockResults = NULL
|
||||
};
|
||||
BMK_runOutcome_t result;
|
||||
|
||||
while (!BMK_isCompleted_TimedFn(txf)) {
|
||||
result = BMK_benchTimedFn(txf, params);
|
||||
assert(BMK_isSuccessful_runOutcome(result));
|
||||
}
|
||||
|
||||
BMK_runTime_t const runTime = BMK_extract_runTime(result);
|
||||
|
||||
free(srcBuffer);
|
||||
assert(runTime.nanoSecPerRun != 0);
|
||||
return (1000000000U / runTime.nanoSecPerRun) * nbBlocks;
|
||||
|
||||
}
|
||||
|
||||
|
||||
static size_t rand_1_N(size_t N) { return ((size_t)rand() % N) + 1; }
|
||||
|
||||
static size_t identity(size_t s) { return s; }
|
||||
|
||||
static size_t
|
||||
benchLatency(const void* src, size_t srcSize,
|
||||
void* dst, size_t dstCapacity,
|
||||
void* customPayload)
|
||||
{
|
||||
(void)dst; (void)dstCapacity;
|
||||
BMK_benchFn_t benchfn = (BMK_benchFn_t)customPayload;
|
||||
static size_t hash = 0;
|
||||
|
||||
const void* const start = (const char*)src + (hash & START_MASK);
|
||||
|
||||
return hash = benchfn(start, srcSize, dst, dstCapacity, NULL);
|
||||
}
|
||||
|
||||
|
||||
|
||||
#ifndef SIZE_TO_HASH_PER_ROUND
|
||||
# define SIZE_TO_HASH_PER_ROUND 200000
|
||||
#endif
|
||||
|
||||
#ifndef NB_HASH_ROUNDS_MAX
|
||||
# define NB_HASH_ROUNDS_MAX 1000
|
||||
#endif
|
||||
|
||||
double bench_hash(BMK_benchFn_t hashfn,
|
||||
BMK_benchMode benchMode,
|
||||
size_t size, BMK_sizeMode sizeMode,
|
||||
unsigned total_time_ms, unsigned iter_time_ms)
|
||||
{
|
||||
sizeFunction_f const sizef = (sizeMode == BMK_fixedSize) ? identity : rand_1_N;
|
||||
BMK_benchFn_t const benchfn = (benchMode == BMK_throughput) ? hashfn : benchLatency;
|
||||
BMK_benchFn_t const payload = (benchMode == BMK_throughput) ? NULL : hashfn;
|
||||
|
||||
size_t nbBlocks = (SIZE_TO_HASH_PER_ROUND / size) + 1;
|
||||
if (nbBlocks > NB_HASH_ROUNDS_MAX) nbBlocks = NB_HASH_ROUNDS_MAX;
|
||||
|
||||
return bench_hash_internal(benchfn, payload,
|
||||
nbBlocks, sizef, size,
|
||||
total_time_ms, iter_time_ms);
|
||||
}
|
||||
|
|
@ -0,0 +1,74 @@
|
|||
/*
|
||||
* Hash benchmark module
|
||||
* Part of xxHash project
|
||||
* Copyright (C) 2019-present, Yann Collet
|
||||
*
|
||||
* BSD 2-Clause License (http://www.opensource.org/licenses/bsd-license.php)
|
||||
*
|
||||
* Redistribution and use in source and binary forms, with or without
|
||||
* modification, are permitted provided that the following conditions are
|
||||
* met:
|
||||
*
|
||||
* * Redistributions of source code must retain the above copyright
|
||||
* notice, this list of conditions and the following disclaimer.
|
||||
* * Redistributions in binary form must reproduce the above
|
||||
* copyright notice, this list of conditions and the following disclaimer
|
||||
* in the documentation and/or other materials provided with the
|
||||
* distribution.
|
||||
*
|
||||
* THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS
|
||||
* "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT
|
||||
* LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR
|
||||
* A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT
|
||||
* OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL,
|
||||
* SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT
|
||||
* LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE,
|
||||
* DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY
|
||||
* THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
|
||||
* (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
|
||||
* OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|
||||
*
|
||||
* You can contact the author at :
|
||||
* - xxHash homepage: http://www.xxhash.com
|
||||
* - xxHash source repository : https://github.com/Cyan4973/xxHash
|
||||
*/
|
||||
|
||||
|
||||
#ifndef BENCH_HASH_H_983426678
|
||||
#define BENCH_HASH_H_983426678
|
||||
|
||||
#if defined (__cplusplus)
|
||||
extern "C" {
|
||||
#endif
|
||||
|
||||
|
||||
/* === Dependencies === */
|
||||
|
||||
#include "benchfn.h" /* BMK_benchFn_t */
|
||||
|
||||
|
||||
/* === Declarations === */
|
||||
|
||||
typedef enum { BMK_throughput, BMK_latency } BMK_benchMode;
|
||||
|
||||
typedef enum { BMK_fixedSize, /* hash always `size` bytes */
|
||||
BMK_randomSize, /* hash a random nb of bytes, between 1 and `size` (inclusive) */
|
||||
} BMK_sizeMode;
|
||||
|
||||
/* bench_hash() :
|
||||
* returns speed expressed as nb hashes per second.
|
||||
* total_time_ms : time spent benchmarking the hash function with given parameters
|
||||
* iter_time_ms : time spent for one round. If multiple rounds are run, bench_hash() will report the speed of best round.
|
||||
*/
|
||||
double bench_hash(BMK_benchFn_t hashfn,
|
||||
BMK_benchMode benchMode,
|
||||
size_t size, BMK_sizeMode sizeMode,
|
||||
unsigned total_time_ms, unsigned iter_time_ms);
|
||||
|
||||
|
||||
|
||||
#if defined (__cplusplus)
|
||||
}
|
||||
#endif
|
||||
|
||||
#endif /* BENCH_HASH_H_983426678 */
|
||||
|
|
@ -0,0 +1,254 @@
|
|||
/*
|
||||
* Copyright (c) 2016-present, Yann Collet, Facebook, Inc.
|
||||
* All rights reserved.
|
||||
*
|
||||
* This source code is licensed under both the BSD-style license (found in the
|
||||
* LICENSE file in the root directory of this source tree) and the GPLv2 (found
|
||||
* in the COPYING file in the root directory of this source tree).
|
||||
* You may select, at your option, one of the above-listed licenses.
|
||||
*/
|
||||
|
||||
|
||||
|
||||
/* *************************************
|
||||
* Includes
|
||||
***************************************/
|
||||
#include <stdlib.h> /* malloc, free */
|
||||
#include <string.h> /* memset */
|
||||
#undef NDEBUG /* assert must not be disabled */
|
||||
#include <assert.h> /* assert */
|
||||
|
||||
#include "timefn.h" /* UTIL_time_t, UTIL_getTime */
|
||||
#include "benchfn.h"
|
||||
|
||||
|
||||
/* *************************************
|
||||
* Constants
|
||||
***************************************/
|
||||
#define TIMELOOP_MICROSEC SEC_TO_MICRO /* 1 second */
|
||||
#define TIMELOOP_NANOSEC (1*1000000000ULL) /* 1 second */
|
||||
|
||||
#define KB *(1 <<10)
|
||||
#define MB *(1 <<20)
|
||||
#define GB *(1U<<30)
|
||||
|
||||
|
||||
/* *************************************
|
||||
* Debug errors
|
||||
***************************************/
|
||||
#if defined(DEBUG) && (DEBUG >= 1)
|
||||
# include <stdio.h> /* fprintf */
|
||||
# define DISPLAY(...) fprintf(stderr, __VA_ARGS__)
|
||||
# define DEBUGOUTPUT(...) { if (DEBUG) DISPLAY(__VA_ARGS__); }
|
||||
#else
|
||||
# define DEBUGOUTPUT(...)
|
||||
#endif
|
||||
|
||||
|
||||
/* error without displaying */
|
||||
#define RETURN_QUIET_ERROR(retValue, ...) { \
|
||||
DEBUGOUTPUT("%s: %i: \n", __FILE__, __LINE__); \
|
||||
DEBUGOUTPUT("Error : "); \
|
||||
DEBUGOUTPUT(__VA_ARGS__); \
|
||||
DEBUGOUTPUT(" \n"); \
|
||||
return retValue; \
|
||||
}
|
||||
|
||||
|
||||
/* *************************************
|
||||
* Benchmarking an arbitrary function
|
||||
***************************************/
|
||||
|
||||
int BMK_isSuccessful_runOutcome(BMK_runOutcome_t outcome)
|
||||
{
|
||||
return outcome.error_tag_never_ever_use_directly == 0;
|
||||
}
|
||||
|
||||
/* warning : this function will stop program execution if outcome is invalid !
|
||||
* check outcome validity first, using BMK_isValid_runResult() */
|
||||
BMK_runTime_t BMK_extract_runTime(BMK_runOutcome_t outcome)
|
||||
{
|
||||
assert(outcome.error_tag_never_ever_use_directly == 0);
|
||||
return outcome.internal_never_ever_use_directly;
|
||||
}
|
||||
|
||||
size_t BMK_extract_errorResult(BMK_runOutcome_t outcome)
|
||||
{
|
||||
assert(outcome.error_tag_never_ever_use_directly != 0);
|
||||
return outcome.error_result_never_ever_use_directly;
|
||||
}
|
||||
|
||||
static BMK_runOutcome_t BMK_runOutcome_error(size_t errorResult)
|
||||
{
|
||||
BMK_runOutcome_t b;
|
||||
memset(&b, 0, sizeof(b));
|
||||
b.error_tag_never_ever_use_directly = 1;
|
||||
b.error_result_never_ever_use_directly = errorResult;
|
||||
return b;
|
||||
}
|
||||
|
||||
static BMK_runOutcome_t BMK_setValid_runTime(BMK_runTime_t runTime)
|
||||
{
|
||||
BMK_runOutcome_t outcome;
|
||||
outcome.error_tag_never_ever_use_directly = 0;
|
||||
outcome.internal_never_ever_use_directly = runTime;
|
||||
return outcome;
|
||||
}
|
||||
|
||||
|
||||
/* initFn will be measured once, benchFn will be measured `nbLoops` times */
|
||||
/* initFn is optional, provide NULL if none */
|
||||
/* benchFn must return a size_t value that errorFn can interpret */
|
||||
/* takes # of blocks and list of size & stuff for each. */
|
||||
/* can report result of benchFn for each block into blockResult. */
|
||||
/* blockResult is optional, provide NULL if this information is not required */
|
||||
/* note : time per loop can be reported as zero if run time < timer resolution */
|
||||
BMK_runOutcome_t BMK_benchFunction(BMK_benchParams_t p,
|
||||
unsigned nbLoops)
|
||||
{
|
||||
size_t dstSize = 0;
|
||||
nbLoops += !nbLoops; /* minimum nbLoops is 1 */
|
||||
|
||||
/* init */
|
||||
{ size_t i;
|
||||
for(i = 0; i < p.blockCount; i++) {
|
||||
memset(p.dstBuffers[i], 0xE5, p.dstCapacities[i]); /* warm up and erase result buffer */
|
||||
} }
|
||||
|
||||
/* benchmark */
|
||||
{ UTIL_time_t const clockStart = UTIL_getTime();
|
||||
unsigned loopNb, blockNb;
|
||||
if (p.initFn != NULL) p.initFn(p.initPayload);
|
||||
for (loopNb = 0; loopNb < nbLoops; loopNb++) {
|
||||
for (blockNb = 0; blockNb < p.blockCount; blockNb++) {
|
||||
size_t const res = p.benchFn(p.srcBuffers[blockNb], p.srcSizes[blockNb],
|
||||
p.dstBuffers[blockNb], p.dstCapacities[blockNb],
|
||||
p.benchPayload);
|
||||
if (loopNb == 0) {
|
||||
if (p.blockResults != NULL) p.blockResults[blockNb] = res;
|
||||
if ((p.errorFn != NULL) && (p.errorFn(res))) {
|
||||
RETURN_QUIET_ERROR(BMK_runOutcome_error(res),
|
||||
"Function benchmark failed on block %u (of size %u) with error %i",
|
||||
blockNb, (unsigned)p.srcSizes[blockNb], (int)res);
|
||||
}
|
||||
dstSize += res;
|
||||
} }
|
||||
} /* for (loopNb = 0; loopNb < nbLoops; loopNb++) */
|
||||
|
||||
{ PTime const totalTime = UTIL_clockSpanNano(clockStart);
|
||||
BMK_runTime_t rt;
|
||||
rt.nanoSecPerRun = (double)totalTime / nbLoops;
|
||||
rt.sumOfReturn = dstSize;
|
||||
return BMK_setValid_runTime(rt);
|
||||
} }
|
||||
}
|
||||
|
||||
|
||||
/* ==== Benchmarking any function, providing intermediate results ==== */
|
||||
|
||||
struct BMK_timedFnState_s {
|
||||
PTime timeSpent_ns;
|
||||
PTime timeBudget_ns;
|
||||
PTime runBudget_ns;
|
||||
BMK_runTime_t fastestRun;
|
||||
unsigned nbLoops;
|
||||
UTIL_time_t coolTime;
|
||||
}; /* typedef'd to BMK_timedFnState_t within bench.h */
|
||||
|
||||
BMK_timedFnState_t* BMK_createTimedFnState(unsigned total_ms, unsigned run_ms)
|
||||
{
|
||||
BMK_timedFnState_t* const r = (BMK_timedFnState_t*)malloc(sizeof(*r));
|
||||
if (r == NULL) return NULL; /* malloc() error */
|
||||
BMK_resetTimedFnState(r, total_ms, run_ms);
|
||||
return r;
|
||||
}
|
||||
|
||||
void BMK_freeTimedFnState(BMK_timedFnState_t* state) { free(state); }
|
||||
|
||||
BMK_timedFnState_t*
|
||||
BMK_initStatic_timedFnState(void* buffer, size_t size, unsigned total_ms, unsigned run_ms)
|
||||
{
|
||||
typedef char check_size[ 2 * (sizeof(BMK_timedFnState_shell) >= sizeof(struct BMK_timedFnState_s)) - 1]; /* static assert : a compilation failure indicates that BMK_timedFnState_shell is not large enough */
|
||||
typedef struct { check_size c; BMK_timedFnState_t tfs; } tfs_align; /* force tfs to be aligned at its next best position */
|
||||
size_t const tfs_alignment = offsetof(tfs_align, tfs); /* provides the minimal alignment restriction for BMK_timedFnState_t */
|
||||
BMK_timedFnState_t* const r = (BMK_timedFnState_t*)buffer;
|
||||
if (buffer == NULL) return NULL;
|
||||
if (size < sizeof(struct BMK_timedFnState_s)) return NULL;
|
||||
if ((size_t)buffer % tfs_alignment) return NULL; /* buffer must be properly aligned */
|
||||
BMK_resetTimedFnState(r, total_ms, run_ms);
|
||||
return r;
|
||||
}
|
||||
|
||||
void BMK_resetTimedFnState(BMK_timedFnState_t* timedFnState, unsigned total_ms, unsigned run_ms)
|
||||
{
|
||||
if (!total_ms) total_ms = 1 ;
|
||||
if (!run_ms) run_ms = 1;
|
||||
if (run_ms > total_ms) run_ms = total_ms;
|
||||
timedFnState->timeSpent_ns = 0;
|
||||
timedFnState->timeBudget_ns = (PTime)total_ms * TIMELOOP_NANOSEC / 1000;
|
||||
timedFnState->runBudget_ns = (PTime)run_ms * TIMELOOP_NANOSEC / 1000;
|
||||
timedFnState->fastestRun.nanoSecPerRun = (double)TIMELOOP_NANOSEC * 2000000000; /* hopefully large enough : must be larger than any potential measurement */
|
||||
timedFnState->fastestRun.sumOfReturn = (size_t)(-1LL);
|
||||
timedFnState->nbLoops = 1;
|
||||
timedFnState->coolTime = UTIL_getTime();
|
||||
}
|
||||
|
||||
/* Tells if nb of seconds set in timedFnState for all runs is spent.
|
||||
* note : this function will return 1 if BMK_benchFunctionTimed() has actually errored. */
|
||||
int BMK_isCompleted_TimedFn(const BMK_timedFnState_t* timedFnState)
|
||||
{
|
||||
return (timedFnState->timeSpent_ns >= timedFnState->timeBudget_ns);
|
||||
}
|
||||
|
||||
|
||||
#undef MIN
|
||||
#define MIN(a,b) ( (a) < (b) ? (a) : (b) )
|
||||
|
||||
#define MINUSABLETIME (TIMELOOP_NANOSEC / 2) /* 0.5 seconds */
|
||||
|
||||
BMK_runOutcome_t BMK_benchTimedFn(BMK_timedFnState_t* cont,
|
||||
BMK_benchParams_t p)
|
||||
{
|
||||
PTime const runBudget_ns = cont->runBudget_ns;
|
||||
PTime const runTimeMin_ns = runBudget_ns / 2;
|
||||
int completed = 0;
|
||||
BMK_runTime_t bestRunTime = cont->fastestRun;
|
||||
|
||||
while (!completed) {
|
||||
BMK_runOutcome_t const runResult = BMK_benchFunction(p, cont->nbLoops);
|
||||
|
||||
if(!BMK_isSuccessful_runOutcome(runResult)) { /* error : move out */
|
||||
return runResult;
|
||||
}
|
||||
|
||||
{ BMK_runTime_t const newRunTime = BMK_extract_runTime(runResult);
|
||||
double const loopDuration_ns = newRunTime.nanoSecPerRun * cont->nbLoops;
|
||||
|
||||
cont->timeSpent_ns += (unsigned long long)loopDuration_ns;
|
||||
|
||||
/* estimate nbLoops for next run to last approximately 1 second */
|
||||
if (loopDuration_ns > (runBudget_ns / 50)) {
|
||||
double const fastestRun_ns = MIN(bestRunTime.nanoSecPerRun, newRunTime.nanoSecPerRun);
|
||||
cont->nbLoops = (unsigned)(runBudget_ns / fastestRun_ns) + 1;
|
||||
} else {
|
||||
/* previous run was too short : blindly increase workload by x multiplier */
|
||||
const unsigned multiplier = 10;
|
||||
assert(cont->nbLoops < ((unsigned)-1) / multiplier); /* avoid overflow */
|
||||
cont->nbLoops *= multiplier;
|
||||
}
|
||||
|
||||
if(loopDuration_ns < runTimeMin_ns) {
|
||||
/* don't report results for which benchmark run time was too small : increased risks of rounding errors */
|
||||
assert(completed == 0);
|
||||
continue;
|
||||
} else {
|
||||
if(newRunTime.nanoSecPerRun < bestRunTime.nanoSecPerRun) {
|
||||
bestRunTime = newRunTime;
|
||||
}
|
||||
completed = 1;
|
||||
}
|
||||
}
|
||||
} /* while (!completed) */
|
||||
|
||||
return BMK_setValid_runTime(bestRunTime);
|
||||
}
|
||||
|
|
@ -0,0 +1,183 @@
|
|||
/*
|
||||
* Copyright (c) 2016-present, Yann Collet, Facebook, Inc.
|
||||
* All rights reserved.
|
||||
*
|
||||
* This source code is licensed under both the BSD-style license (found in the
|
||||
* LICENSE file in the root directory of this source tree) and the GPLv2 (found
|
||||
* in the COPYING file in the root directory of this source tree).
|
||||
* You may select, at your option, one of the above-listed licenses.
|
||||
*/
|
||||
|
||||
|
||||
/* benchfn :
|
||||
* benchmark any function on a set of input
|
||||
* providing result in nanoSecPerRun
|
||||
* or detecting and returning an error
|
||||
*/
|
||||
|
||||
#if defined (__cplusplus)
|
||||
extern "C" {
|
||||
#endif
|
||||
|
||||
#ifndef BENCH_FN_H_23876
|
||||
#define BENCH_FN_H_23876
|
||||
|
||||
/* === Dependencies === */
|
||||
#include <stddef.h> /* size_t */
|
||||
|
||||
|
||||
/* ==== Benchmark any function, iterated on a set of blocks ==== */
|
||||
|
||||
/* BMK_runTime_t: valid result return type */
|
||||
|
||||
typedef struct {
|
||||
double nanoSecPerRun; /* time per iteration (over all blocks) */
|
||||
size_t sumOfReturn; /* sum of return values */
|
||||
} BMK_runTime_t;
|
||||
|
||||
|
||||
/* BMK_runOutcome_t:
|
||||
* type expressing the outcome of a benchmark run by BMK_benchFunction(),
|
||||
* which can be either valid or invalid.
|
||||
* benchmark outcome can be invalid if errorFn is provided.
|
||||
* BMK_runOutcome_t must be considered "opaque" : never access its members directly.
|
||||
* Instead, use its assigned methods :
|
||||
* BMK_isSuccessful_runOutcome, BMK_extract_runTime, BMK_extract_errorResult.
|
||||
* The structure is only described here to allow its allocation on stack. */
|
||||
|
||||
typedef struct {
|
||||
BMK_runTime_t internal_never_ever_use_directly;
|
||||
size_t error_result_never_ever_use_directly;
|
||||
int error_tag_never_ever_use_directly;
|
||||
} BMK_runOutcome_t;
|
||||
|
||||
|
||||
/* prototypes for benchmarked functions */
|
||||
typedef size_t (*BMK_benchFn_t)(const void* src, size_t srcSize, void* dst, size_t dstCapacity, void* customPayload);
|
||||
typedef size_t (*BMK_initFn_t)(void* initPayload);
|
||||
typedef unsigned (*BMK_errorFn_t)(size_t);
|
||||
|
||||
|
||||
/* BMK_benchFunction() parameters are provided via the following structure.
|
||||
* A structure is preferable for readability,
|
||||
* as the number of parameters required is fairly large.
|
||||
* No initializer is provided, because it doesn't make sense to provide some "default" :
|
||||
* all parameters must be specified by the caller.
|
||||
* optional parameters are labelled explicitly, and accept value NULL when not used */
|
||||
typedef struct {
|
||||
BMK_benchFn_t benchFn; /* the function to benchmark, over the set of blocks */
|
||||
void* benchPayload; /* pass custom parameters to benchFn :
|
||||
* (*benchFn)(srcBuffers[i], srcSizes[i], dstBuffers[i], dstCapacities[i], benchPayload) */
|
||||
BMK_initFn_t initFn; /* (*initFn)(initPayload) is run once per run, at the beginning. */
|
||||
void* initPayload; /* Both arguments can be NULL, in which case nothing is run. */
|
||||
BMK_errorFn_t errorFn; /* errorFn will check each return value of benchFn over each block, to determine if it failed or not.
|
||||
* errorFn can be NULL, in which case no check is performed.
|
||||
* errorFn must return 0 when benchFn was successful, and >= 1 if it detects an error.
|
||||
* Execution is stopped as soon as an error is detected.
|
||||
* the triggering return value can be retrieved using BMK_extract_errorResult(). */
|
||||
size_t blockCount; /* number of blocks to operate benchFn on.
|
||||
* It's also the size of all array parameters :
|
||||
* srcBuffers, srcSizes, dstBuffers, dstCapacities, blockResults */
|
||||
const void *const * srcBuffers; /* read-only array of buffers to be operated on by benchFn */
|
||||
const size_t* srcSizes; /* read-only array containing sizes of srcBuffers */
|
||||
void *const * dstBuffers; /* array of buffers to be written into by benchFn. This array is not optional, it must be provided even if unused by benchfn. */
|
||||
const size_t* dstCapacities; /* read-only array containing capacities of dstBuffers. This array must be present. */
|
||||
size_t* blockResults; /* Optional: store the return value of benchFn for each block. Use NULL if this result is not requested. */
|
||||
} BMK_benchParams_t;
|
||||
|
||||
|
||||
/* BMK_benchFunction() :
|
||||
* This function benchmarks benchFn and initFn, providing a result.
|
||||
*
|
||||
* params : see description of BMK_benchParams_t above.
|
||||
* nbLoops: defines number of times benchFn is run over the full set of blocks.
|
||||
* Minimum value is 1. A 0 is interpreted as a 1.
|
||||
*
|
||||
* @return: can express either an error or a successful result.
|
||||
* Use BMK_isSuccessful_runOutcome() to check if benchmark was successful.
|
||||
* If yes, extract the result with BMK_extract_runTime(),
|
||||
* it will contain :
|
||||
* .sumOfReturn : the sum of all return values of benchFn through all of blocks
|
||||
* .nanoSecPerRun : time per run of benchFn + (time for initFn / nbLoops)
|
||||
* .sumOfReturn is generally intended for functions which return a # of bytes written into dstBuffer,
|
||||
* in which case, this value will be the total amount of bytes written into dstBuffer.
|
||||
*
|
||||
* blockResults : when provided (!= NULL), and when benchmark is successful,
|
||||
* params.blockResults contains all return values of `benchFn` over all blocks.
|
||||
* when provided (!= NULL), and when benchmark failed,
|
||||
* params.blockResults contains return values of `benchFn` over all blocks preceding and including the failed block.
|
||||
*/
|
||||
BMK_runOutcome_t BMK_benchFunction(BMK_benchParams_t params, unsigned nbLoops);
|
||||
|
||||
|
||||
|
||||
/* check first if the benchmark was successful or not */
|
||||
int BMK_isSuccessful_runOutcome(BMK_runOutcome_t outcome);
|
||||
|
||||
/* If the benchmark was successful, extract the result.
|
||||
* note : this function will abort() program execution if benchmark failed !
|
||||
* always check if benchmark was successful first !
|
||||
*/
|
||||
BMK_runTime_t BMK_extract_runTime(BMK_runOutcome_t outcome);
|
||||
|
||||
/* when benchmark failed, it means one invocation of `benchFn` failed.
|
||||
* The failure was detected by `errorFn`, operating on return values of `benchFn`.
|
||||
* Returns the faulty return value.
|
||||
* note : this function will abort() program execution if benchmark did not failed.
|
||||
* always check if benchmark failed first !
|
||||
*/
|
||||
size_t BMK_extract_errorResult(BMK_runOutcome_t outcome);
|
||||
|
||||
|
||||
|
||||
/* ==== Benchmark any function, returning intermediate results ==== */
|
||||
|
||||
/* state information tracking benchmark session */
|
||||
typedef struct BMK_timedFnState_s BMK_timedFnState_t;
|
||||
|
||||
/* BMK_benchTimedFn() :
|
||||
* Similar to BMK_benchFunction(), most arguments being identical.
|
||||
* Automatically determines `nbLoops` so that each result is regularly produced at interval of about run_ms.
|
||||
* Note : minimum `nbLoops` is 1, therefore a run may last more than run_ms, and possibly even more than total_ms.
|
||||
* Usage - initialize timedFnState, select benchmark duration (total_ms) and each measurement duration (run_ms)
|
||||
* call BMK_benchTimedFn() repetitively, each measurement is supposed to last about run_ms
|
||||
* Check if total time budget is spent or exceeded, using BMK_isCompleted_TimedFn()
|
||||
*/
|
||||
BMK_runOutcome_t BMK_benchTimedFn(BMK_timedFnState_t* timedFnState,
|
||||
BMK_benchParams_t params);
|
||||
|
||||
/* Tells if duration of all benchmark runs has exceeded total_ms
|
||||
*/
|
||||
int BMK_isCompleted_TimedFn(const BMK_timedFnState_t* timedFnState);
|
||||
|
||||
/* BMK_createTimedFnState() and BMK_resetTimedFnState() :
|
||||
* Create/Set BMK_timedFnState_t for next benchmark session,
|
||||
* which shall last a minimum of total_ms milliseconds,
|
||||
* producing intermediate results, paced at interval of (approximately) run_ms.
|
||||
*/
|
||||
BMK_timedFnState_t* BMK_createTimedFnState(unsigned total_ms, unsigned run_ms);
|
||||
void BMK_resetTimedFnState(BMK_timedFnState_t* timedFnState, unsigned total_ms, unsigned run_ms);
|
||||
void BMK_freeTimedFnState(BMK_timedFnState_t* state);
|
||||
|
||||
|
||||
/* BMK_timedFnState_shell and BMK_initStatic_timedFnState() :
|
||||
* Makes it possible to statically allocate a BMK_timedFnState_t on stack.
|
||||
* BMK_timedFnState_shell is only there to allocate space,
|
||||
* never ever access its members.
|
||||
* BMK_timedFnState_t() actually accepts any buffer.
|
||||
* It will check if provided buffer is large enough and is correctly aligned,
|
||||
* and will return NULL if conditions are not respected.
|
||||
*/
|
||||
#define BMK_TIMEDFNSTATE_SIZE 64
|
||||
typedef union {
|
||||
char never_access_space[BMK_TIMEDFNSTATE_SIZE];
|
||||
long long alignment_enforcer; /* must be aligned on 8-bytes boundaries */
|
||||
} BMK_timedFnState_shell;
|
||||
BMK_timedFnState_t* BMK_initStatic_timedFnState(void* buffer, size_t size, unsigned total_ms, unsigned run_ms);
|
||||
|
||||
|
||||
#endif /* BENCH_FN_H_23876 */
|
||||
|
||||
#if defined (__cplusplus)
|
||||
}
|
||||
#endif
|
||||
|
|
@ -0,0 +1,168 @@
|
|||
/*
|
||||
* CSV Display module for the hash benchmark program
|
||||
* Part of xxHash project
|
||||
* Copyright (C) 2019-present, Yann Collet
|
||||
*
|
||||
* BSD 2-Clause License (http://www.opensource.org/licenses/bsd-license.php)
|
||||
*
|
||||
* Redistribution and use in source and binary forms, with or without
|
||||
* modification, are permitted provided that the following conditions are
|
||||
* met:
|
||||
*
|
||||
* * Redistributions of source code must retain the above copyright
|
||||
* notice, this list of conditions and the following disclaimer.
|
||||
* * Redistributions in binary form must reproduce the above
|
||||
* copyright notice, this list of conditions and the following disclaimer
|
||||
* in the documentation and/or other materials provided with the
|
||||
* distribution.
|
||||
*
|
||||
* THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS
|
||||
* "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT
|
||||
* LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR
|
||||
* A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT
|
||||
* OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL,
|
||||
* SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT
|
||||
* LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE,
|
||||
* DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY
|
||||
* THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
|
||||
* (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
|
||||
* OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|
||||
*
|
||||
* You can contact the author at :
|
||||
* - xxHash homepage: http://www.xxhash.com
|
||||
* - xxHash source repository : https://github.com/Cyan4973/xxHash
|
||||
*/
|
||||
|
||||
|
||||
/* === Dependencies === */
|
||||
|
||||
#include <stdlib.h> /* rand */
|
||||
#include <stdio.h> /* printf */
|
||||
#include <assert.h>
|
||||
|
||||
#include "benchHash.h"
|
||||
#include "bhDisplay.h"
|
||||
|
||||
|
||||
/* === benchmark large input === */
|
||||
|
||||
#define MB_UNIT 1000000
|
||||
#define BENCH_LARGE_ITER_MS 490
|
||||
#define BENCH_LARGE_TOTAL_MS 1010
|
||||
static void bench_oneHash_largeInput(Bench_Entry hashDesc, int minlog, int maxlog)
|
||||
{
|
||||
printf("%-7s", hashDesc.name);
|
||||
for (int sizelog=minlog; sizelog<=maxlog; sizelog++) {
|
||||
size_t const inputSize = (size_t)1 << sizelog;
|
||||
double const nbhps = bench_hash(hashDesc.hash, BMK_throughput,
|
||||
inputSize, BMK_fixedSize,
|
||||
BENCH_LARGE_TOTAL_MS, BENCH_LARGE_ITER_MS);
|
||||
printf(",%9.1f", nbhps * inputSize / MB_UNIT); fflush(NULL);
|
||||
}
|
||||
printf("\n");
|
||||
}
|
||||
|
||||
void bench_largeInput(Bench_Entry const* hashDescTable, int nbHashes, int minlog, int maxlog)
|
||||
{
|
||||
assert(maxlog < 31);
|
||||
assert(minlog >= 0);
|
||||
printf("benchmarking large inputs : from %u bytes (log%i) to %u MB (log%i) \n",
|
||||
1U << minlog, minlog,
|
||||
(1U << maxlog) >> 20, maxlog);
|
||||
for (int i=0; i<nbHashes; i++)
|
||||
bench_oneHash_largeInput(hashDescTable[i], minlog, maxlog);
|
||||
}
|
||||
|
||||
|
||||
|
||||
/* === benchmark small input === */
|
||||
|
||||
#define BENCH_SMALL_ITER_MS 170
|
||||
#define BENCH_SMALL_TOTAL_MS 490
|
||||
static void bench_throughput_oneHash_smallInputs(Bench_Entry hashDesc, size_t sizeMin, size_t sizeMax)
|
||||
{
|
||||
printf("%-7s", hashDesc.name);
|
||||
for (size_t s=sizeMin; s<sizeMax+1; s++) {
|
||||
double const nbhps = bench_hash(hashDesc.hash, BMK_throughput,
|
||||
s, BMK_fixedSize,
|
||||
BENCH_SMALL_TOTAL_MS, BENCH_SMALL_ITER_MS);
|
||||
printf(",%11.1f", nbhps); fflush(NULL);
|
||||
}
|
||||
printf("\n");
|
||||
}
|
||||
|
||||
void bench_throughput_smallInputs(Bench_Entry const* hashDescTable, int nbHashes, size_t sizeMin, size_t sizeMax)
|
||||
{
|
||||
printf("Throughput small inputs of fixed size : \n");
|
||||
for (int i=0; i<nbHashes; i++)
|
||||
bench_throughput_oneHash_smallInputs(hashDescTable[i], sizeMin, sizeMax);
|
||||
}
|
||||
|
||||
|
||||
|
||||
/* === Latency measurements (small keys) === */
|
||||
|
||||
static void bench_latency_oneHash_smallInputs(Bench_Entry hashDesc, size_t size_min, size_t size_max)
|
||||
{
|
||||
printf("%-7s", hashDesc.name);
|
||||
for (size_t s=size_min; s<size_max+1; s++) {
|
||||
double const nbhps = bench_hash(hashDesc.hash, BMK_latency,
|
||||
s, BMK_fixedSize,
|
||||
BENCH_SMALL_TOTAL_MS, BENCH_SMALL_ITER_MS);
|
||||
printf(",%11.1f", nbhps); fflush(NULL);
|
||||
}
|
||||
printf("\n");
|
||||
}
|
||||
|
||||
void bench_latency_smallInputs(Bench_Entry const* hashDescTable, int nbHashes, size_t size_min, size_t size_max)
|
||||
{
|
||||
printf("Latency for small inputs of fixed size : \n");
|
||||
for (int i=0; i<nbHashes; i++)
|
||||
bench_latency_oneHash_smallInputs(hashDescTable[i], size_min, size_max);
|
||||
}
|
||||
|
||||
|
||||
/* === Random input Length === */
|
||||
|
||||
static void bench_randomInputLength_withOneHash(Bench_Entry hashDesc, size_t size_min, size_t size_max)
|
||||
{
|
||||
printf("%-7s", hashDesc.name);
|
||||
for (size_t s=size_min; s<size_max+1; s++) {
|
||||
srand((unsigned)s); /* ensure random sequence of length will be the same for a given s */
|
||||
double const nbhps = bench_hash(hashDesc.hash, BMK_throughput,
|
||||
s, BMK_randomSize,
|
||||
BENCH_SMALL_TOTAL_MS, BENCH_SMALL_ITER_MS);
|
||||
printf(",%11.1f", nbhps); fflush(NULL);
|
||||
}
|
||||
printf("\n");
|
||||
}
|
||||
|
||||
void bench_throughput_randomInputLength(Bench_Entry const* hashDescTable, int nbHashes, size_t size_min, size_t size_max)
|
||||
{
|
||||
printf("benchmarking random size inputs [1-N] : \n");
|
||||
for (int i=0; i<nbHashes; i++)
|
||||
bench_randomInputLength_withOneHash(hashDescTable[i], size_min, size_max);
|
||||
}
|
||||
|
||||
|
||||
/* === Latency with Random input Length === */
|
||||
|
||||
static void bench_latency_oneHash_randomInputLength(Bench_Entry hashDesc, size_t size_min, size_t size_max)
|
||||
{
|
||||
printf("%-7s", hashDesc.name);
|
||||
for (size_t s=size_min; s<size_max+1; s++) {
|
||||
srand((unsigned)s); /* ensure random sequence of length will be the same for a given s */
|
||||
double const nbhps = bench_hash(hashDesc.hash, BMK_latency,
|
||||
s, BMK_randomSize,
|
||||
BENCH_SMALL_TOTAL_MS, BENCH_SMALL_ITER_MS);
|
||||
printf(",%11.1f", nbhps); fflush(NULL);
|
||||
}
|
||||
printf("\n");
|
||||
}
|
||||
|
||||
void bench_latency_randomInputLength(Bench_Entry const* hashDescTable, int nbHashes, size_t size_min, size_t size_max)
|
||||
{
|
||||
printf("Latency for small inputs of random size [1-N] : \n");
|
||||
for (int i=0; i<nbHashes; i++)
|
||||
bench_latency_oneHash_randomInputLength(hashDescTable[i], size_min, size_max);
|
||||
}
|
||||
|
|
@ -0,0 +1,70 @@
|
|||
/*
|
||||
* CSV Display module for the hash benchmark program
|
||||
* Part of xxHash project
|
||||
* Copyright (C) 2019-present, Yann Collet
|
||||
*
|
||||
* BSD 2-Clause License (http://www.opensource.org/licenses/bsd-license.php)
|
||||
*
|
||||
* Redistribution and use in source and binary forms, with or without
|
||||
* modification, are permitted provided that the following conditions are
|
||||
* met:
|
||||
*
|
||||
* * Redistributions of source code must retain the above copyright
|
||||
* notice, this list of conditions and the following disclaimer.
|
||||
* * Redistributions in binary form must reproduce the above
|
||||
* copyright notice, this list of conditions and the following disclaimer
|
||||
* in the documentation and/or other materials provided with the
|
||||
* distribution.
|
||||
*
|
||||
* THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS
|
||||
* "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT
|
||||
* LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR
|
||||
* A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT
|
||||
* OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL,
|
||||
* SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT
|
||||
* LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE,
|
||||
* DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY
|
||||
* THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
|
||||
* (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
|
||||
* OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|
||||
*
|
||||
* You can contact the author at :
|
||||
* - xxHash homepage: http://www.xxhash.com
|
||||
* - xxHash source repository : https://github.com/Cyan4973/xxHash
|
||||
*/
|
||||
|
||||
#ifndef BH_DISPLAY_H_192088098
|
||||
#define BH_DISPLAY_H_192088098
|
||||
|
||||
#if defined (__cplusplus)
|
||||
extern "C" {
|
||||
#endif
|
||||
|
||||
|
||||
/* === Dependencies === */
|
||||
|
||||
#include "benchfn.h" /* BMK_benchFn_t */
|
||||
|
||||
|
||||
/* === Declarations === */
|
||||
|
||||
typedef struct {
|
||||
const char* name;
|
||||
BMK_benchFn_t hash;
|
||||
} Bench_Entry;
|
||||
|
||||
void bench_largeInput(Bench_Entry const* hashDescTable, int nbHashes, int sizeLogMin, int sizeLogMax);
|
||||
|
||||
void bench_throughput_smallInputs(Bench_Entry const* hashDescTable, int nbHashes, size_t sizeMin, size_t sizeMax);
|
||||
void bench_throughput_randomInputLength(Bench_Entry const* hashDescTable, int nbHashes, size_t sizeMin, size_t sizeMax);
|
||||
|
||||
void bench_latency_smallInputs(Bench_Entry const* hashDescTable, int nbHashes, size_t sizeMin, size_t sizeMax);
|
||||
void bench_latency_randomInputLength(Bench_Entry const* hashDescTable, int nbHashes, size_t sizeMin, size_t sizeMax);
|
||||
|
||||
|
||||
|
||||
#if defined (__cplusplus)
|
||||
}
|
||||
#endif
|
||||
|
||||
#endif /* BH_DISPLAY_H_192088098 */
|
||||
|
|
@ -0,0 +1,127 @@
|
|||
/*
|
||||
* List hash algorithms to benchmark
|
||||
* Part of xxHash project
|
||||
* Copyright (C) 2019-present, Yann Collet
|
||||
*
|
||||
* BSD 2-Clause License (http://www.opensource.org/licenses/bsd-license.php)
|
||||
*
|
||||
* Redistribution and use in source and binary forms, with or without
|
||||
* modification, are permitted provided that the following conditions are
|
||||
* met:
|
||||
*
|
||||
* * Redistributions of source code must retain the above copyright
|
||||
* notice, this list of conditions and the following disclaimer.
|
||||
* * Redistributions in binary form must reproduce the above
|
||||
* copyright notice, this list of conditions and the following disclaimer
|
||||
* in the documentation and/or other materials provided with the
|
||||
* distribution.
|
||||
*
|
||||
* THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS
|
||||
* "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT
|
||||
* LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR
|
||||
* A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT
|
||||
* OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL,
|
||||
* SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT
|
||||
* LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE,
|
||||
* DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY
|
||||
* THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
|
||||
* (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
|
||||
* OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|
||||
*
|
||||
* You can contact the author at :
|
||||
* - xxHash homepage: http://www.xxhash.com
|
||||
* - xxHash source repository : https://github.com/Cyan4973/xxHash
|
||||
*/
|
||||
|
||||
|
||||
/* === Dependencies === */
|
||||
|
||||
#include <stddef.h> /* size_t */
|
||||
|
||||
|
||||
/* ==================================================
|
||||
* Non-portable hash algorithms
|
||||
* =============================================== */
|
||||
|
||||
|
||||
#ifdef HARDWARE_SUPPORT
|
||||
|
||||
/* list here hash algorithms depending on specific hardware support,
|
||||
* including for example :
|
||||
* - Hardware crc32c
|
||||
* - Hardware AES support
|
||||
* - Carryless Multipliers (clmul)
|
||||
* - AVX2
|
||||
*/
|
||||
|
||||
#endif
|
||||
|
||||
|
||||
|
||||
/* ==================================================
|
||||
* List of hashes
|
||||
* =============================================== */
|
||||
|
||||
/* Each hash must be wrapped in a thin redirector conformant with the BMK_benchfn_t.
|
||||
* BMK_benchfn_t is generic, not specifically designed for hashes.
|
||||
* For hashes, the following parameters are expected to be useless :
|
||||
* dst, dstCapacity, customPayload.
|
||||
*
|
||||
* The result of each hash is assumed to be provided as function return value.
|
||||
* This condition is important for latency measurements.
|
||||
*/
|
||||
|
||||
/* === xxHash === */
|
||||
|
||||
#include "xxh3.h"
|
||||
|
||||
size_t XXH32_wrapper(const void* src, size_t srcSize, void* dst, size_t dstCapacity, void* customPayload)
|
||||
{
|
||||
(void)dst; (void)dstCapacity; (void)customPayload;
|
||||
return (size_t) XXH32(src, srcSize, 0);
|
||||
}
|
||||
|
||||
|
||||
size_t XXH64_wrapper(const void* src, size_t srcSize, void* dst, size_t dstCapacity, void* customPayload)
|
||||
{
|
||||
(void)dst; (void)dstCapacity; (void)customPayload;
|
||||
return (size_t) XXH64(src, srcSize, 0);
|
||||
}
|
||||
|
||||
|
||||
size_t xxh3_wrapper(const void* src, size_t srcSize, void* dst, size_t dstCapacity, void* customPayload)
|
||||
{
|
||||
(void)dst; (void)dstCapacity; (void)customPayload;
|
||||
return (size_t) XXH3_64bits(src, srcSize);
|
||||
}
|
||||
|
||||
|
||||
size_t XXH128_wrapper(const void* src, size_t srcSize, void* dst, size_t dstCapacity, void* customPayload)
|
||||
{
|
||||
(void)dst; (void)dstCapacity; (void)customPayload;
|
||||
return (size_t) XXH3_128bits(src, srcSize).low64;
|
||||
}
|
||||
|
||||
|
||||
|
||||
/* ==================================================
|
||||
* Table of hashes
|
||||
* =============================================== */
|
||||
|
||||
#include "bhDisplay.h" /* Bench_Entry */
|
||||
|
||||
#ifndef HARDWARE_SUPPORT
|
||||
# define NB_HASHES 4
|
||||
#else
|
||||
# define NB_HASHES 4
|
||||
#endif
|
||||
|
||||
Bench_Entry const hashCandidates[NB_HASHES] = {
|
||||
{ "xxh3" , xxh3_wrapper },
|
||||
{ "XXH32" , XXH32_wrapper },
|
||||
{ "XXH64" , XXH64_wrapper },
|
||||
{ "XXH128", XXH128_wrapper },
|
||||
#ifdef HARDWARE_SUPPORT
|
||||
/* list here codecs which require specific hardware support, such SSE4.1, PCLMUL, AVX2, etc. */
|
||||
#endif
|
||||
};
|
||||
|
|
@ -0,0 +1,217 @@
|
|||
/*
|
||||
* Main program to benchmark hash functions
|
||||
* Part of xxHash project
|
||||
* Copyright (C) 2019-present, Yann Collet
|
||||
*
|
||||
* BSD 2-Clause License (http://www.opensource.org/licenses/bsd-license.php)
|
||||
*
|
||||
* Redistribution and use in source and binary forms, with or without
|
||||
* modification, are permitted provided that the following conditions are
|
||||
* met:
|
||||
*
|
||||
* * Redistributions of source code must retain the above copyright
|
||||
* notice, this list of conditions and the following disclaimer.
|
||||
* * Redistributions in binary form must reproduce the above
|
||||
* copyright notice, this list of conditions and the following disclaimer
|
||||
* in the documentation and/or other materials provided with the
|
||||
* distribution.
|
||||
*
|
||||
* THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS
|
||||
* "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT
|
||||
* LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR
|
||||
* A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT
|
||||
* OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL,
|
||||
* SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT
|
||||
* LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE,
|
||||
* DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY
|
||||
* THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
|
||||
* (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
|
||||
* OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|
||||
*
|
||||
* You can contact the author at :
|
||||
* - xxHash homepage: http://www.xxhash.com
|
||||
* - xxHash source repository : https://github.com/Cyan4973/xxHash
|
||||
*/
|
||||
|
||||
|
||||
/* === dependencies === */
|
||||
|
||||
#include <stdio.h> /* printf */
|
||||
#include <limits.h> /* INT_MAX */
|
||||
#include "bhDisplay.h" /* bench_x */
|
||||
|
||||
|
||||
/* === defines list of hashes `hashCandidates` and NB_HASHES *** */
|
||||
|
||||
#include "hashes.h"
|
||||
|
||||
|
||||
/* === parse command line === */
|
||||
|
||||
#undef NDEBUG
|
||||
#include <assert.h>
|
||||
|
||||
|
||||
/*! readIntFromChar() :
|
||||
* allows and interprets K, KB, KiB, M, MB and MiB suffix.
|
||||
* Will also modify `*stringPtr`, advancing it to position where it stopped reading.
|
||||
*/
|
||||
static int readIntFromChar(const char** stringPtr)
|
||||
{
|
||||
static int const max = (INT_MAX / 10) - 1;
|
||||
int result = 0;
|
||||
while ((**stringPtr >='0') && (**stringPtr <='9')) {
|
||||
assert(result < max);
|
||||
result *= 10;
|
||||
result += (unsigned)(**stringPtr - '0');
|
||||
(*stringPtr)++ ;
|
||||
}
|
||||
if ((**stringPtr=='K') || (**stringPtr=='M')) {
|
||||
int const maxK = INT_MAX >> 10;
|
||||
assert(result < maxK);
|
||||
result <<= 10;
|
||||
if (**stringPtr=='M') {
|
||||
assert(result < maxK);
|
||||
result <<= 10;
|
||||
}
|
||||
(*stringPtr)++; /* skip `K` or `M` */
|
||||
if (**stringPtr=='i') (*stringPtr)++;
|
||||
if (**stringPtr=='B') (*stringPtr)++;
|
||||
}
|
||||
return result;
|
||||
}
|
||||
|
||||
|
||||
/** longCommand() :
|
||||
* check if string is the same as longCommand.
|
||||
* If yes, @return 1 and advances *stringPtr to the position which immediately follows longCommand.
|
||||
* @return 0 and doesn't modify *stringPtr otherwise.
|
||||
*/
|
||||
static int isCommand(const char* stringPtr, const char* longCommand)
|
||||
{
|
||||
size_t const comSize = strlen(longCommand);
|
||||
assert(stringPtr); assert(longCommand);
|
||||
return !strncmp(stringPtr, longCommand, comSize);
|
||||
}
|
||||
|
||||
/** longCommandWArg() :
|
||||
* check if *stringPtr is the same as longCommand.
|
||||
* If yes, @return 1 and advances *stringPtr to the position which immediately follows longCommand.
|
||||
* @return 0 and doesn't modify *stringPtr otherwise.
|
||||
*/
|
||||
static int longCommandWArg(const char** stringPtr, const char* longCommand)
|
||||
{
|
||||
size_t const comSize = strlen(longCommand);
|
||||
int const result = isCommand(*stringPtr, longCommand);
|
||||
if (result) *stringPtr += comSize;
|
||||
return result;
|
||||
}
|
||||
|
||||
|
||||
/* === default values - can be redefined at compilation time === */
|
||||
|
||||
#ifndef SMALL_SIZE_MIN_DEFAULT
|
||||
# define SMALL_SIZE_MIN_DEFAULT 1
|
||||
#endif
|
||||
#ifndef SMALL_SIZE_MAX_DEFAULT
|
||||
# define SMALL_SIZE_MAX_DEFAULT 127
|
||||
#endif
|
||||
#ifndef LARGE_SIZELOG_MIN_DEFAULT
|
||||
# define LARGE_SIZELOG_MIN_DEFAULT 9
|
||||
#endif
|
||||
#ifndef LARGE_SIZELOG_MAX_DEFAULT
|
||||
# define LARGE_SIZELOG_MAX_DEFAULT 27
|
||||
#endif
|
||||
|
||||
|
||||
static int display_hash_names(void)
|
||||
{
|
||||
int i;
|
||||
printf("available hashes : \n");
|
||||
for (i=0; i<NB_HASHES; i++) {
|
||||
printf("%s, ", hashCandidates[i].name);
|
||||
}
|
||||
printf("\b\b \n");
|
||||
return 0;
|
||||
}
|
||||
|
||||
/* @return : hashID (necessarily between 0 and NB_HASHES) if present
|
||||
* -1 on error (hname not present)
|
||||
*/
|
||||
static int hashID(const char* hname)
|
||||
{
|
||||
int id;
|
||||
assert(hname);
|
||||
for (id=0; id < NB_HASHES; id++) {
|
||||
assert(hashCandidates[id].name);
|
||||
if (strlen(hname) != strlen(hashCandidates[id].name)) continue;
|
||||
if (isCommand(hname, hashCandidates[id].name)) return id;
|
||||
}
|
||||
return -1;
|
||||
}
|
||||
|
||||
static int help(const char* exename)
|
||||
{
|
||||
printf("usage : %s [options] [hash] \n\n", exename);
|
||||
printf("Options: \n");
|
||||
printf("--list : name available hash algorithms and exit \n");
|
||||
printf("--mins=# : starting length for small size bench (default:%i) \n", SMALL_SIZE_MIN_DEFAULT);
|
||||
printf("--maxs=# : end length for small size bench (default:%i) \n", SMALL_SIZE_MAX_DEFAULT);
|
||||
printf("--minl=# : starting log2(length) for large size bench (default:%i) \n", LARGE_SIZELOG_MIN_DEFAULT);
|
||||
printf("--maxl=# : end log2(length) for large size bench (default:%i) \n", LARGE_SIZELOG_MAX_DEFAULT);
|
||||
printf("[hash] : is optional, bench all available hashes if not provided \n");
|
||||
return 0;
|
||||
}
|
||||
|
||||
static int badusage(const char* exename)
|
||||
{
|
||||
printf("Bad command ... \n");
|
||||
help(exename);
|
||||
return 1;
|
||||
}
|
||||
|
||||
int main(int argc, const char** argv)
|
||||
{
|
||||
const char* const exename = argv[0];
|
||||
int hashNb = 0;
|
||||
int nb_h_test = NB_HASHES;
|
||||
int largeTest_log_min = LARGE_SIZELOG_MIN_DEFAULT;
|
||||
int largeTest_log_max = LARGE_SIZELOG_MAX_DEFAULT;
|
||||
size_t smallTest_size_min = SMALL_SIZE_MIN_DEFAULT;
|
||||
size_t smallTest_size_max = SMALL_SIZE_MAX_DEFAULT;
|
||||
|
||||
int arg_nb;
|
||||
for (arg_nb = 1; arg_nb < argc; arg_nb++) {
|
||||
const char** arg = argv + arg_nb;
|
||||
if (isCommand(*arg, "-h")) { assert(argc >= 1); return help(exename); }
|
||||
if (isCommand(*arg, "--list")) { return display_hash_names(); }
|
||||
if (longCommandWArg(arg, "--n=")) { nb_h_test = readIntFromChar(arg); continue; } /* hidden command */
|
||||
if (longCommandWArg(arg, "--minl=")) { largeTest_log_min = readIntFromChar(arg); continue; }
|
||||
if (longCommandWArg(arg, "--maxl=")) { largeTest_log_max = readIntFromChar(arg); continue; }
|
||||
if (longCommandWArg(arg, "--mins=")) { smallTest_size_min = (size_t)readIntFromChar(arg); continue; }
|
||||
if (longCommandWArg(arg, "--maxs=")) { smallTest_size_max = (size_t)readIntFromChar(arg); continue; }
|
||||
/* not a command : must be a hash name */
|
||||
hashNb = hashID(*arg);
|
||||
if (hashNb >= 0) {
|
||||
nb_h_test = 1;
|
||||
} else {
|
||||
/* not a hash name : error */
|
||||
return badusage(exename);
|
||||
}
|
||||
}
|
||||
|
||||
if (hashNb + nb_h_test > NB_HASHES) { printf("wrong hash selection \n"); return 1; } /* border case (requires (mis)using hidden command `--n=#`) */
|
||||
|
||||
printf(" === benchmarking %i hash functions === \n", nb_h_test);
|
||||
if (largeTest_log_max >= largeTest_log_min) {
|
||||
bench_largeInput(hashCandidates+hashNb, nb_h_test, largeTest_log_min, largeTest_log_max);
|
||||
}
|
||||
if (smallTest_size_max >= smallTest_size_min) {
|
||||
bench_throughput_smallInputs(hashCandidates+hashNb, nb_h_test, smallTest_size_min, smallTest_size_max);
|
||||
bench_throughput_randomInputLength(hashCandidates+hashNb, nb_h_test, smallTest_size_min, smallTest_size_max);
|
||||
bench_latency_smallInputs(hashCandidates+hashNb, nb_h_test, smallTest_size_min, smallTest_size_max);
|
||||
bench_latency_randomInputLength(hashCandidates+hashNb, nb_h_test, smallTest_size_min, smallTest_size_max);
|
||||
}
|
||||
|
||||
return 0;
|
||||
}
|
||||
|
|
@ -0,0 +1,168 @@
|
|||
/*
|
||||
* Copyright (c) 2019-present, Yann Collet, Facebook, Inc.
|
||||
* All rights reserved.
|
||||
*
|
||||
* This source code is licensed under both the BSD-style license (found in the
|
||||
* LICENSE file in the root directory of this source tree) and the GPLv2 (found
|
||||
* in the COPYING file in the root directory of this source tree).
|
||||
* You may select, at your option, one of the above-listed licenses.
|
||||
*/
|
||||
|
||||
|
||||
/* === Dependencies === */
|
||||
|
||||
#include "timefn.h"
|
||||
|
||||
|
||||
/*-****************************************
|
||||
* Time functions
|
||||
******************************************/
|
||||
|
||||
#if defined(_WIN32) /* Windows */
|
||||
|
||||
#include <stdlib.h> /* abort */
|
||||
#include <stdio.h> /* perror */
|
||||
|
||||
UTIL_time_t UTIL_getTime(void) { UTIL_time_t x; QueryPerformanceCounter(&x); return x; }
|
||||
|
||||
PTime UTIL_getSpanTimeMicro(UTIL_time_t clockStart, UTIL_time_t clockEnd)
|
||||
{
|
||||
static LARGE_INTEGER ticksPerSecond;
|
||||
static int init = 0;
|
||||
if (!init) {
|
||||
if (!QueryPerformanceFrequency(&ticksPerSecond)) {
|
||||
perror("timefn::QueryPerformanceFrequency");
|
||||
abort();
|
||||
}
|
||||
init = 1;
|
||||
}
|
||||
return 1000000ULL*(clockEnd.QuadPart - clockStart.QuadPart)/ticksPerSecond.QuadPart;
|
||||
}
|
||||
|
||||
PTime UTIL_getSpanTimeNano(UTIL_time_t clockStart, UTIL_time_t clockEnd)
|
||||
{
|
||||
static LARGE_INTEGER ticksPerSecond;
|
||||
static int init = 0;
|
||||
if (!init) {
|
||||
if (!QueryPerformanceFrequency(&ticksPerSecond)) {
|
||||
perror("timefn::QueryPerformanceFrequency");
|
||||
abort();
|
||||
}
|
||||
init = 1;
|
||||
}
|
||||
return 1000000000ULL*(clockEnd.QuadPart - clockStart.QuadPart)/ticksPerSecond.QuadPart;
|
||||
}
|
||||
|
||||
|
||||
|
||||
#elif defined(__APPLE__) && defined(__MACH__)
|
||||
|
||||
UTIL_time_t UTIL_getTime(void) { return mach_absolute_time(); }
|
||||
|
||||
PTime UTIL_getSpanTimeMicro(UTIL_time_t clockStart, UTIL_time_t clockEnd)
|
||||
{
|
||||
static mach_timebase_info_data_t rate;
|
||||
static int init = 0;
|
||||
if (!init) {
|
||||
mach_timebase_info(&rate);
|
||||
init = 1;
|
||||
}
|
||||
return (((clockEnd - clockStart) * (PTime)rate.numer) / ((PTime)rate.denom))/1000ULL;
|
||||
}
|
||||
|
||||
PTime UTIL_getSpanTimeNano(UTIL_time_t clockStart, UTIL_time_t clockEnd)
|
||||
{
|
||||
static mach_timebase_info_data_t rate;
|
||||
static int init = 0;
|
||||
if (!init) {
|
||||
mach_timebase_info(&rate);
|
||||
init = 1;
|
||||
}
|
||||
return ((clockEnd - clockStart) * (PTime)rate.numer) / ((PTime)rate.denom);
|
||||
}
|
||||
|
||||
|
||||
|
||||
#elif (defined (__STDC_VERSION__) && (__STDC_VERSION__ >= 201112L) /* C11 */) \
|
||||
&& defined(TIME_UTC) /* C11 requires timespec_get, but FreeBSD 11 lacks it, while still claiming C11 compliance */
|
||||
|
||||
#include <stdlib.h> /* abort */
|
||||
#include <stdio.h> /* perror */
|
||||
|
||||
UTIL_time_t UTIL_getTime(void)
|
||||
{
|
||||
/* time must be initialized, othersize it may fail msan test.
|
||||
* No good reason, likely a limitation of timespec_get() for some target */
|
||||
UTIL_time_t time = UTIL_TIME_INITIALIZER;
|
||||
if (timespec_get(&time, TIME_UTC) != TIME_UTC) {
|
||||
perror("timefn::timespec_get");
|
||||
abort();
|
||||
}
|
||||
return time;
|
||||
}
|
||||
|
||||
static UTIL_time_t UTIL_getSpanTime(UTIL_time_t begin, UTIL_time_t end)
|
||||
{
|
||||
UTIL_time_t diff;
|
||||
if (end.tv_nsec < begin.tv_nsec) {
|
||||
diff.tv_sec = (end.tv_sec - 1) - begin.tv_sec;
|
||||
diff.tv_nsec = (end.tv_nsec + 1000000000ULL) - begin.tv_nsec;
|
||||
} else {
|
||||
diff.tv_sec = end.tv_sec - begin.tv_sec;
|
||||
diff.tv_nsec = end.tv_nsec - begin.tv_nsec;
|
||||
}
|
||||
return diff;
|
||||
}
|
||||
|
||||
PTime UTIL_getSpanTimeMicro(UTIL_time_t begin, UTIL_time_t end)
|
||||
{
|
||||
UTIL_time_t const diff = UTIL_getSpanTime(begin, end);
|
||||
PTime micro = 0;
|
||||
micro += 1000000ULL * diff.tv_sec;
|
||||
micro += diff.tv_nsec / 1000ULL;
|
||||
return micro;
|
||||
}
|
||||
|
||||
PTime UTIL_getSpanTimeNano(UTIL_time_t begin, UTIL_time_t end)
|
||||
{
|
||||
UTIL_time_t const diff = UTIL_getSpanTime(begin, end);
|
||||
PTime nano = 0;
|
||||
nano += 1000000000ULL * diff.tv_sec;
|
||||
nano += diff.tv_nsec;
|
||||
return nano;
|
||||
}
|
||||
|
||||
|
||||
|
||||
#else /* relies on standard C90 (note : clock_t measurements can be wrong when using multi-threading) */
|
||||
|
||||
UTIL_time_t UTIL_getTime(void) { return clock(); }
|
||||
PTime UTIL_getSpanTimeMicro(UTIL_time_t clockStart, UTIL_time_t clockEnd) { return 1000000ULL * (clockEnd - clockStart) / CLOCKS_PER_SEC; }
|
||||
PTime UTIL_getSpanTimeNano(UTIL_time_t clockStart, UTIL_time_t clockEnd) { return 1000000000ULL * (clockEnd - clockStart) / CLOCKS_PER_SEC; }
|
||||
|
||||
#endif
|
||||
|
||||
|
||||
|
||||
/* returns time span in microseconds */
|
||||
PTime UTIL_clockSpanMicro(UTIL_time_t clockStart )
|
||||
{
|
||||
UTIL_time_t const clockEnd = UTIL_getTime();
|
||||
return UTIL_getSpanTimeMicro(clockStart, clockEnd);
|
||||
}
|
||||
|
||||
/* returns time span in microseconds */
|
||||
PTime UTIL_clockSpanNano(UTIL_time_t clockStart )
|
||||
{
|
||||
UTIL_time_t const clockEnd = UTIL_getTime();
|
||||
return UTIL_getSpanTimeNano(clockStart, clockEnd);
|
||||
}
|
||||
|
||||
void UTIL_waitForNextTick(void)
|
||||
{
|
||||
UTIL_time_t const clockStart = UTIL_getTime();
|
||||
UTIL_time_t clockEnd;
|
||||
do {
|
||||
clockEnd = UTIL_getTime();
|
||||
} while (UTIL_getSpanTimeNano(clockStart, clockEnd) == 0);
|
||||
}
|
||||
|
|
@ -0,0 +1,89 @@
|
|||
/*
|
||||
* Copyright (c) 2016-present, Yann Collet, Facebook, Inc.
|
||||
* All rights reserved.
|
||||
*
|
||||
* This source code is licensed under both the BSD-style license (found in the
|
||||
* LICENSE file in the root directory of this source tree) and the GPLv2 (found
|
||||
* in the COPYING file in the root directory of this source tree).
|
||||
* You may select, at your option, one of the above-listed licenses.
|
||||
*/
|
||||
|
||||
#ifndef TIME_FN_H_MODULE_287987
|
||||
#define TIME_FN_H_MODULE_287987
|
||||
|
||||
#if defined (__cplusplus)
|
||||
extern "C" {
|
||||
#endif
|
||||
|
||||
|
||||
/*-****************************************
|
||||
* Dependencies
|
||||
******************************************/
|
||||
#include <sys/types.h> /* utime */
|
||||
#if defined(_MSC_VER)
|
||||
# include <sys/utime.h> /* utime */
|
||||
#else
|
||||
# include <utime.h> /* utime */
|
||||
#endif
|
||||
#include <time.h> /* clock_t, clock, CLOCKS_PER_SEC */
|
||||
|
||||
|
||||
|
||||
/*-****************************************
|
||||
* Local Types
|
||||
******************************************/
|
||||
|
||||
#if !defined (__VMS) && (defined (__cplusplus) || (defined (__STDC_VERSION__) && (__STDC_VERSION__ >= 199901L) /* C99 */) )
|
||||
# include <stdint.h>
|
||||
typedef uint64_t PTime; /* Precise Time */
|
||||
#else
|
||||
typedef unsigned long long PTime; /* does not support compilers without long long support */
|
||||
#endif
|
||||
|
||||
|
||||
|
||||
/*-****************************************
|
||||
* Time functions
|
||||
******************************************/
|
||||
#if defined(_WIN32) /* Windows */
|
||||
|
||||
#include <Windows.h> /* LARGE_INTEGER */
|
||||
typedef LARGE_INTEGER UTIL_time_t;
|
||||
#define UTIL_TIME_INITIALIZER { { 0, 0 } }
|
||||
|
||||
#elif defined(__APPLE__) && defined(__MACH__)
|
||||
|
||||
#include <mach/mach_time.h>
|
||||
typedef PTime UTIL_time_t;
|
||||
#define UTIL_TIME_INITIALIZER 0
|
||||
|
||||
#elif (defined (__STDC_VERSION__) && (__STDC_VERSION__ >= 201112L) /* C11 */) \
|
||||
&& defined(TIME_UTC) /* C11 requires timespec_get, but FreeBSD 11 lacks it, while still claiming C11 compliance */
|
||||
|
||||
typedef struct timespec UTIL_time_t;
|
||||
#define UTIL_TIME_INITIALIZER { 0, 0 }
|
||||
|
||||
#else /* relies on standard C90 (note : clock_t measurements can be wrong when using multi-threading) */
|
||||
|
||||
typedef clock_t UTIL_time_t;
|
||||
#define UTIL_TIME_INITIALIZER 0
|
||||
|
||||
#endif
|
||||
|
||||
|
||||
UTIL_time_t UTIL_getTime(void);
|
||||
PTime UTIL_getSpanTimeMicro(UTIL_time_t clockStart, UTIL_time_t clockEnd);
|
||||
PTime UTIL_getSpanTimeNano(UTIL_time_t clockStart, UTIL_time_t clockEnd);
|
||||
|
||||
#define SEC_TO_MICRO ((PTime)1000000)
|
||||
PTime UTIL_clockSpanMicro(UTIL_time_t clockStart);
|
||||
PTime UTIL_clockSpanNano(UTIL_time_t clockStart);
|
||||
|
||||
void UTIL_waitForNextTick(void);
|
||||
|
||||
|
||||
#if defined (__cplusplus)
|
||||
}
|
||||
#endif
|
||||
|
||||
#endif /* TIME_FN_H_MODULE_287987 */
|
||||
File diff suppressed because it is too large
Load Diff
|
|
@ -71,18 +71,6 @@
|
|||
# define XXH_ACCEPT_NULL_INPUT_POINTER 0
|
||||
#endif
|
||||
|
||||
/*!XXH_FORCE_NATIVE_FORMAT :
|
||||
* By default, xxHash library provides endian-independent Hash values, based on little-endian convention.
|
||||
* Results are therefore identical for little-endian and big-endian CPU.
|
||||
* This comes at a performance cost for big-endian CPU, since some swapping is required to emulate little-endian format.
|
||||
* Should endian-independence be of no importance for your application, you may set the #define below to 1,
|
||||
* to improve speed for Big-endian CPU.
|
||||
* This option has no impact on Little_Endian CPU.
|
||||
*/
|
||||
#ifndef XXH_FORCE_NATIVE_FORMAT /* can be defined externally */
|
||||
# define XXH_FORCE_NATIVE_FORMAT 0
|
||||
#endif
|
||||
|
||||
/*!XXH_FORCE_ALIGN_CHECK :
|
||||
* This is a minor performance trick, only useful with lots of very small keys.
|
||||
* It means : check for aligned/unaligned input.
|
||||
|
|
@ -98,6 +86,18 @@
|
|||
# endif
|
||||
#endif
|
||||
|
||||
/*!XXH_REROLL:
|
||||
* Whether to reroll XXH32_finalize, and XXH64_finalize,
|
||||
* instead of using an unrolled jump table/if statement loop.
|
||||
*
|
||||
* This is automatically defined on -Os/-Oz on GCC and Clang. */
|
||||
#ifndef XXH_REROLL
|
||||
# if defined(__OPTIMIZE_SIZE__)
|
||||
# define XXH_REROLL 1
|
||||
# else
|
||||
# define XXH_REROLL 0
|
||||
# endif
|
||||
#endif
|
||||
|
||||
/* *************************************
|
||||
* Includes & Memory related functions
|
||||
|
|
@ -111,7 +111,7 @@ static void XXH_free (void* p) { free(p); }
|
|||
#include <string.h>
|
||||
static void* XXH_memcpy(void* dest, const void* src, size_t size) { return memcpy(dest,src,size); }
|
||||
|
||||
#include <assert.h> /* assert */
|
||||
#include <limits.h> /* ULLONG_MAX */
|
||||
|
||||
#define XXH_STATIC_LINKING_ONLY
|
||||
#include "xxhash.h"
|
||||
|
|
@ -122,20 +122,46 @@ static void* XXH_memcpy(void* dest, const void* src, size_t size) { return memcp
|
|||
***************************************/
|
||||
#ifdef _MSC_VER /* Visual Studio */
|
||||
# pragma warning(disable : 4127) /* disable: C4127: conditional expression is constant */
|
||||
# define FORCE_INLINE static __forceinline
|
||||
# define XXH_FORCE_INLINE static __forceinline
|
||||
# define XXH_NO_INLINE static __declspec(noinline)
|
||||
#else
|
||||
# if defined (__cplusplus) || defined (__STDC_VERSION__) && __STDC_VERSION__ >= 199901L /* C99 */
|
||||
# ifdef __GNUC__
|
||||
# define FORCE_INLINE static inline __attribute__((always_inline))
|
||||
# define XXH_FORCE_INLINE static inline __attribute__((always_inline))
|
||||
# define XXH_NO_INLINE static __attribute__((noinline))
|
||||
# else
|
||||
# define FORCE_INLINE static inline
|
||||
# define XXH_FORCE_INLINE static inline
|
||||
# define XXH_NO_INLINE static
|
||||
# endif
|
||||
# else
|
||||
# define FORCE_INLINE static
|
||||
# define XXH_FORCE_INLINE static
|
||||
# define XXH_NO_INLINE static
|
||||
# endif /* __STDC_VERSION__ */
|
||||
#endif
|
||||
|
||||
|
||||
|
||||
/* *************************************
|
||||
* Debug
|
||||
***************************************/
|
||||
/* DEBUGLEVEL is expected to be defined externally,
|
||||
* typically through compiler command line.
|
||||
* Value must be a number. */
|
||||
#ifndef DEBUGLEVEL
|
||||
# define DEBUGLEVEL 0
|
||||
#endif
|
||||
|
||||
#if (DEBUGLEVEL>=1)
|
||||
# include <assert.h> /* note : can still be disabled with NDEBUG */
|
||||
# define XXH_ASSERT(c) assert(c)
|
||||
#else
|
||||
# define XXH_ASSERT(c) ((void)0)
|
||||
#endif
|
||||
|
||||
/* note : use after variable declarations */
|
||||
#define XXH_STATIC_ASSERT(c) { enum { XXH_sa = 1/(int)(!!(c)) }; }
|
||||
|
||||
|
||||
/* *************************************
|
||||
* Basic Types
|
||||
***************************************/
|
||||
|
|
@ -154,6 +180,9 @@ static void* XXH_memcpy(void* dest, const void* src, size_t size) { return memcp
|
|||
# endif
|
||||
#endif
|
||||
|
||||
|
||||
/* === Memory access === */
|
||||
|
||||
#if (defined(XXH_FORCE_MEMORY_ACCESS) && (XXH_FORCE_MEMORY_ACCESS==2))
|
||||
|
||||
/* Force direct memory access. Only works on CPU which support unaligned memory access in hardware */
|
||||
|
|
@ -181,18 +210,41 @@ static U32 XXH_read32(const void* memPtr)
|
|||
#endif /* XXH_FORCE_DIRECT_MEMORY_ACCESS */
|
||||
|
||||
|
||||
/* === Endianess === */
|
||||
typedef enum { XXH_bigEndian=0, XXH_littleEndian=1 } XXH_endianess;
|
||||
|
||||
/* XXH_CPU_LITTLE_ENDIAN can be defined externally, for example on the compiler command line */
|
||||
#ifndef XXH_CPU_LITTLE_ENDIAN
|
||||
static int XXH_isLittleEndian(void)
|
||||
{
|
||||
const union { U32 u; BYTE c[4]; } one = { 1 }; /* don't use static : performance detrimental */
|
||||
return one.c[0];
|
||||
}
|
||||
# define XXH_CPU_LITTLE_ENDIAN XXH_isLittleEndian()
|
||||
#endif
|
||||
|
||||
|
||||
|
||||
|
||||
/* ****************************************
|
||||
* Compiler-specific Functions and Macros
|
||||
******************************************/
|
||||
#define XXH_GCC_VERSION (__GNUC__ * 100 + __GNUC_MINOR__)
|
||||
|
||||
#ifndef __has_builtin
|
||||
# define __has_builtin(x) 0
|
||||
#endif
|
||||
|
||||
#if !defined(NO_CLANG_BUILTIN) && __has_builtin(__builtin_rotateleft32) && __has_builtin(__builtin_rotateleft64)
|
||||
# define XXH_rotl32 __builtin_rotateleft32
|
||||
# define XXH_rotl64 __builtin_rotateleft64
|
||||
/* Note : although _rotl exists for minGW (GCC under windows), performance seems poor */
|
||||
#if defined(_MSC_VER)
|
||||
#elif defined(_MSC_VER)
|
||||
# define XXH_rotl32(x,r) _rotl(x,r)
|
||||
# define XXH_rotl64(x,r) _rotl64(x,r)
|
||||
#else
|
||||
# define XXH_rotl32(x,r) ((x << r) | (x >> (32 - r)))
|
||||
# define XXH_rotl64(x,r) ((x << r) | (x >> (64 - r)))
|
||||
# define XXH_rotl32(x,r) (((x) << (r)) | ((x) >> (32 - (r))))
|
||||
# define XXH_rotl64(x,r) (((x) << (r)) | ((x) >> (64 - (r))))
|
||||
#endif
|
||||
|
||||
#if defined(_MSC_VER) /* Visual Studio */
|
||||
|
|
@ -210,38 +262,14 @@ static U32 XXH_swap32 (U32 x)
|
|||
#endif
|
||||
|
||||
|
||||
/* *************************************
|
||||
* Architecture Macros
|
||||
***************************************/
|
||||
typedef enum { XXH_bigEndian=0, XXH_littleEndian=1 } XXH_endianess;
|
||||
|
||||
/* XXH_CPU_LITTLE_ENDIAN can be defined externally, for example on the compiler command line */
|
||||
#ifndef XXH_CPU_LITTLE_ENDIAN
|
||||
static int XXH_isLittleEndian(void)
|
||||
{
|
||||
const union { U32 u; BYTE c[4]; } one = { 1 }; /* don't use static : performance detrimental */
|
||||
return one.c[0];
|
||||
}
|
||||
# define XXH_CPU_LITTLE_ENDIAN XXH_isLittleEndian()
|
||||
#endif
|
||||
|
||||
|
||||
/* ***************************
|
||||
* Memory reads
|
||||
*****************************/
|
||||
typedef enum { XXH_aligned, XXH_unaligned } XXH_alignment;
|
||||
|
||||
FORCE_INLINE U32 XXH_readLE32_align(const void* ptr, XXH_endianess endian, XXH_alignment align)
|
||||
XXH_FORCE_INLINE U32 XXH_readLE32(const void* ptr)
|
||||
{
|
||||
if (align==XXH_unaligned)
|
||||
return endian==XXH_littleEndian ? XXH_read32(ptr) : XXH_swap32(XXH_read32(ptr));
|
||||
else
|
||||
return endian==XXH_littleEndian ? *(const U32*)ptr : XXH_swap32(*(const U32*)ptr);
|
||||
}
|
||||
|
||||
FORCE_INLINE U32 XXH_readLE32(const void* ptr, XXH_endianess endian)
|
||||
{
|
||||
return XXH_readLE32_align(ptr, endian, XXH_unaligned);
|
||||
return XXH_CPU_LITTLE_ENDIAN ? XXH_read32(ptr) : XXH_swap32(XXH_read32(ptr));
|
||||
}
|
||||
|
||||
static U32 XXH_readBE32(const void* ptr)
|
||||
|
|
@ -249,29 +277,82 @@ static U32 XXH_readBE32(const void* ptr)
|
|||
return XXH_CPU_LITTLE_ENDIAN ? XXH_swap32(XXH_read32(ptr)) : XXH_read32(ptr);
|
||||
}
|
||||
|
||||
XXH_FORCE_INLINE U32
|
||||
XXH_readLE32_align(const void* ptr, XXH_alignment align)
|
||||
{
|
||||
if (align==XXH_unaligned) {
|
||||
return XXH_readLE32(ptr);
|
||||
} else {
|
||||
return XXH_CPU_LITTLE_ENDIAN ? *(const U32*)ptr : XXH_swap32(*(const U32*)ptr);
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
/* *************************************
|
||||
* Macros
|
||||
* Misc
|
||||
***************************************/
|
||||
#define XXH_STATIC_ASSERT(c) { enum { XXH_sa = 1/(int)(!!(c)) }; } /* use after variable declarations */
|
||||
XXH_PUBLIC_API unsigned XXH_versionNumber (void) { return XXH_VERSION_NUMBER; }
|
||||
|
||||
|
||||
/* *******************************************************************
|
||||
* 32-bit hash functions
|
||||
*********************************************************************/
|
||||
static const U32 PRIME32_1 = 2654435761U;
|
||||
static const U32 PRIME32_2 = 2246822519U;
|
||||
static const U32 PRIME32_3 = 3266489917U;
|
||||
static const U32 PRIME32_4 = 668265263U;
|
||||
static const U32 PRIME32_5 = 374761393U;
|
||||
static const U32 PRIME32_1 = 0x9E3779B1U; /* 0b10011110001101110111100110110001 */
|
||||
static const U32 PRIME32_2 = 0x85EBCA77U; /* 0b10000101111010111100101001110111 */
|
||||
static const U32 PRIME32_3 = 0xC2B2AE3DU; /* 0b11000010101100101010111000111101 */
|
||||
static const U32 PRIME32_4 = 0x27D4EB2FU; /* 0b00100111110101001110101100101111 */
|
||||
static const U32 PRIME32_5 = 0x165667B1U; /* 0b00010110010101100110011110110001 */
|
||||
|
||||
static U32 XXH32_round(U32 seed, U32 input)
|
||||
static U32 XXH32_round(U32 acc, U32 input)
|
||||
{
|
||||
seed += input * PRIME32_2;
|
||||
seed = XXH_rotl32(seed, 13);
|
||||
seed *= PRIME32_1;
|
||||
return seed;
|
||||
acc += input * PRIME32_2;
|
||||
acc = XXH_rotl32(acc, 13);
|
||||
acc *= PRIME32_1;
|
||||
#if defined(__GNUC__) && defined(__SSE4_1__) && !defined(XXH_ENABLE_AUTOVECTORIZE)
|
||||
/* UGLY HACK:
|
||||
* This inline assembly hack forces acc into a normal register. This is the
|
||||
* only thing that prevents GCC and Clang from autovectorizing the XXH32 loop
|
||||
* (pragmas and attributes don't work for some resason) without globally
|
||||
* disabling SSE4.1.
|
||||
*
|
||||
* The reason we want to avoid vectorization is because despite working on
|
||||
* 4 integers at a time, there are multiple factors slowing XXH32 down on
|
||||
* SSE4:
|
||||
* - There's a ridiculous amount of lag from pmulld (10 cycles of latency on newer chips!)
|
||||
* making it slightly slower to multiply four integers at once compared to four
|
||||
* integers independently. Even when pmulld was fastest, Sandy/Ivy Bridge, it is
|
||||
* still not worth it to go into SSE just to multiply unless doing a long operation.
|
||||
*
|
||||
* - Four instructions are required to rotate,
|
||||
* movqda tmp, v // not required with VEX encoding
|
||||
* pslld tmp, 13 // tmp <<= 13
|
||||
* psrld v, 19 // x >>= 19
|
||||
* por v, tmp // x |= tmp
|
||||
* compared to one for scalar:
|
||||
* roll v, 13 // reliably fast across the board
|
||||
* shldl v, v, 13 // Sandy Bridge and later prefer this for some reason
|
||||
*
|
||||
* - Instruction level parallelism is actually more beneficial here because the
|
||||
* SIMD actually serializes this operation: While v1 is rotating, v2 can load data,
|
||||
* while v3 can multiply. SSE forces them to operate together.
|
||||
*
|
||||
* How this hack works:
|
||||
* __asm__("" // Declare an assembly block but don't declare any instructions
|
||||
* : // However, as an Input/Output Operand,
|
||||
* "+r" // constrain a read/write operand (+) as a general purpose register (r).
|
||||
* (acc) // and set acc as the operand
|
||||
* );
|
||||
*
|
||||
* Because of the 'r', the compiler has promised that seed will be in a
|
||||
* general purpose register and the '+' says that it will be 'read/write',
|
||||
* so it has to assume it has changed. It is like volatile without all the
|
||||
* loads and stores.
|
||||
*
|
||||
* Since the argument has to be in a normal register (not an SSE register),
|
||||
* each time XXH32_round is called, it is impossible to vectorize. */
|
||||
__asm__("" : "+r" (acc));
|
||||
#endif
|
||||
return acc;
|
||||
}
|
||||
|
||||
/* mix all bits */
|
||||
|
|
@ -285,12 +366,10 @@ static U32 XXH32_avalanche(U32 h32)
|
|||
return(h32);
|
||||
}
|
||||
|
||||
#define XXH_get32bits(p) XXH_readLE32_align(p, endian, align)
|
||||
#define XXH_get32bits(p) XXH_readLE32_align(p, align)
|
||||
|
||||
static U32
|
||||
XXH32_finalize(U32 h32, const void* ptr, size_t len,
|
||||
XXH_endianess endian, XXH_alignment align)
|
||||
|
||||
XXH32_finalize(U32 h32, const void* ptr, size_t len, XXH_alignment align)
|
||||
{
|
||||
const BYTE* p = (const BYTE*)ptr;
|
||||
|
||||
|
|
@ -303,54 +382,65 @@ XXH32_finalize(U32 h32, const void* ptr, size_t len,
|
|||
p+=4; \
|
||||
h32 = XXH_rotl32(h32, 17) * PRIME32_4 ;
|
||||
|
||||
switch(len&15) /* or switch(bEnd - p) */
|
||||
{
|
||||
case 12: PROCESS4;
|
||||
/* fallthrough */
|
||||
case 8: PROCESS4;
|
||||
/* fallthrough */
|
||||
case 4: PROCESS4;
|
||||
return XXH32_avalanche(h32);
|
||||
/* Compact rerolled version */
|
||||
if (XXH_REROLL) {
|
||||
len &= 15;
|
||||
while (len >= 4) {
|
||||
PROCESS4;
|
||||
len -= 4;
|
||||
}
|
||||
while (len > 0) {
|
||||
PROCESS1;
|
||||
--len;
|
||||
}
|
||||
return XXH32_avalanche(h32);
|
||||
} else {
|
||||
switch(len&15) /* or switch(bEnd - p) */ {
|
||||
case 12: PROCESS4;
|
||||
/* fallthrough */
|
||||
case 8: PROCESS4;
|
||||
/* fallthrough */
|
||||
case 4: PROCESS4;
|
||||
return XXH32_avalanche(h32);
|
||||
|
||||
case 13: PROCESS4;
|
||||
/* fallthrough */
|
||||
case 9: PROCESS4;
|
||||
/* fallthrough */
|
||||
case 5: PROCESS4;
|
||||
PROCESS1;
|
||||
return XXH32_avalanche(h32);
|
||||
case 13: PROCESS4;
|
||||
/* fallthrough */
|
||||
case 9: PROCESS4;
|
||||
/* fallthrough */
|
||||
case 5: PROCESS4;
|
||||
PROCESS1;
|
||||
return XXH32_avalanche(h32);
|
||||
|
||||
case 14: PROCESS4;
|
||||
/* fallthrough */
|
||||
case 10: PROCESS4;
|
||||
/* fallthrough */
|
||||
case 6: PROCESS4;
|
||||
PROCESS1;
|
||||
PROCESS1;
|
||||
return XXH32_avalanche(h32);
|
||||
case 14: PROCESS4;
|
||||
/* fallthrough */
|
||||
case 10: PROCESS4;
|
||||
/* fallthrough */
|
||||
case 6: PROCESS4;
|
||||
PROCESS1;
|
||||
PROCESS1;
|
||||
return XXH32_avalanche(h32);
|
||||
|
||||
case 15: PROCESS4;
|
||||
/* fallthrough */
|
||||
case 11: PROCESS4;
|
||||
/* fallthrough */
|
||||
case 7: PROCESS4;
|
||||
/* fallthrough */
|
||||
case 3: PROCESS1;
|
||||
/* fallthrough */
|
||||
case 2: PROCESS1;
|
||||
/* fallthrough */
|
||||
case 1: PROCESS1;
|
||||
/* fallthrough */
|
||||
case 0: return XXH32_avalanche(h32);
|
||||
case 15: PROCESS4;
|
||||
/* fallthrough */
|
||||
case 11: PROCESS4;
|
||||
/* fallthrough */
|
||||
case 7: PROCESS4;
|
||||
/* fallthrough */
|
||||
case 3: PROCESS1;
|
||||
/* fallthrough */
|
||||
case 2: PROCESS1;
|
||||
/* fallthrough */
|
||||
case 1: PROCESS1;
|
||||
/* fallthrough */
|
||||
case 0: return XXH32_avalanche(h32);
|
||||
}
|
||||
XXH_ASSERT(0);
|
||||
return h32; /* reaching this point is deemed impossible */
|
||||
}
|
||||
assert(0);
|
||||
return h32; /* reaching this point is deemed impossible */
|
||||
}
|
||||
|
||||
|
||||
FORCE_INLINE U32
|
||||
XXH32_endian_align(const void* input, size_t len, U32 seed,
|
||||
XXH_endianess endian, XXH_alignment align)
|
||||
XXH_FORCE_INLINE U32
|
||||
XXH32_endian_align(const void* input, size_t len, U32 seed, XXH_alignment align)
|
||||
{
|
||||
const BYTE* p = (const BYTE*)input;
|
||||
const BYTE* bEnd = p + len;
|
||||
|
|
@ -385,7 +475,7 @@ XXH32_endian_align(const void* input, size_t len, U32 seed,
|
|||
|
||||
h32 += (U32)len;
|
||||
|
||||
return XXH32_finalize(h32, p, len&15, endian, align);
|
||||
return XXH32_finalize(h32, p, len&15, align);
|
||||
}
|
||||
|
||||
|
||||
|
|
@ -397,21 +487,15 @@ XXH_PUBLIC_API unsigned int XXH32 (const void* input, size_t len, unsigned int s
|
|||
XXH32_reset(&state, seed);
|
||||
XXH32_update(&state, input, len);
|
||||
return XXH32_digest(&state);
|
||||
|
||||
#else
|
||||
XXH_endianess endian_detected = (XXH_endianess)XXH_CPU_LITTLE_ENDIAN;
|
||||
|
||||
if (XXH_FORCE_ALIGN_CHECK) {
|
||||
if ((((size_t)input) & 3) == 0) { /* Input is 4-bytes aligned, leverage the speed benefit */
|
||||
if ((endian_detected==XXH_littleEndian) || XXH_FORCE_NATIVE_FORMAT)
|
||||
return XXH32_endian_align(input, len, seed, XXH_littleEndian, XXH_aligned);
|
||||
else
|
||||
return XXH32_endian_align(input, len, seed, XXH_bigEndian, XXH_aligned);
|
||||
return XXH32_endian_align(input, len, seed, XXH_aligned);
|
||||
} }
|
||||
|
||||
if ((endian_detected==XXH_littleEndian) || XXH_FORCE_NATIVE_FORMAT)
|
||||
return XXH32_endian_align(input, len, seed, XXH_littleEndian, XXH_unaligned);
|
||||
else
|
||||
return XXH32_endian_align(input, len, seed, XXH_bigEndian, XXH_unaligned);
|
||||
return XXH32_endian_align(input, len, seed, XXH_unaligned);
|
||||
#endif
|
||||
}
|
||||
|
||||
|
|
@ -448,8 +532,8 @@ XXH_PUBLIC_API XXH_errorcode XXH32_reset(XXH32_state_t* statePtr, unsigned int s
|
|||
}
|
||||
|
||||
|
||||
FORCE_INLINE XXH_errorcode
|
||||
XXH32_update_endian(XXH32_state_t* state, const void* input, size_t len, XXH_endianess endian)
|
||||
XXH_PUBLIC_API XXH_errorcode
|
||||
XXH32_update(XXH32_state_t* state, const void* input, size_t len)
|
||||
{
|
||||
if (input==NULL)
|
||||
#if defined(XXH_ACCEPT_NULL_INPUT_POINTER) && (XXH_ACCEPT_NULL_INPUT_POINTER>=1)
|
||||
|
|
@ -461,22 +545,22 @@ XXH32_update_endian(XXH32_state_t* state, const void* input, size_t len, XXH_end
|
|||
{ const BYTE* p = (const BYTE*)input;
|
||||
const BYTE* const bEnd = p + len;
|
||||
|
||||
state->total_len_32 += (unsigned)len;
|
||||
state->large_len |= (len>=16) | (state->total_len_32>=16);
|
||||
state->total_len_32 += (XXH32_hash_t)len;
|
||||
state->large_len |= (XXH32_hash_t)((len>=16) | (state->total_len_32>=16));
|
||||
|
||||
if (state->memsize + len < 16) { /* fill in tmp buffer */
|
||||
XXH_memcpy((BYTE*)(state->mem32) + state->memsize, input, len);
|
||||
state->memsize += (unsigned)len;
|
||||
state->memsize += (XXH32_hash_t)len;
|
||||
return XXH_OK;
|
||||
}
|
||||
|
||||
if (state->memsize) { /* some data left from previous update */
|
||||
XXH_memcpy((BYTE*)(state->mem32) + state->memsize, input, 16-state->memsize);
|
||||
{ const U32* p32 = state->mem32;
|
||||
state->v1 = XXH32_round(state->v1, XXH_readLE32(p32, endian)); p32++;
|
||||
state->v2 = XXH32_round(state->v2, XXH_readLE32(p32, endian)); p32++;
|
||||
state->v3 = XXH32_round(state->v3, XXH_readLE32(p32, endian)); p32++;
|
||||
state->v4 = XXH32_round(state->v4, XXH_readLE32(p32, endian));
|
||||
state->v1 = XXH32_round(state->v1, XXH_readLE32(p32)); p32++;
|
||||
state->v2 = XXH32_round(state->v2, XXH_readLE32(p32)); p32++;
|
||||
state->v3 = XXH32_round(state->v3, XXH_readLE32(p32)); p32++;
|
||||
state->v4 = XXH32_round(state->v4, XXH_readLE32(p32));
|
||||
}
|
||||
p += 16-state->memsize;
|
||||
state->memsize = 0;
|
||||
|
|
@ -490,10 +574,10 @@ XXH32_update_endian(XXH32_state_t* state, const void* input, size_t len, XXH_end
|
|||
U32 v4 = state->v4;
|
||||
|
||||
do {
|
||||
v1 = XXH32_round(v1, XXH_readLE32(p, endian)); p+=4;
|
||||
v2 = XXH32_round(v2, XXH_readLE32(p, endian)); p+=4;
|
||||
v3 = XXH32_round(v3, XXH_readLE32(p, endian)); p+=4;
|
||||
v4 = XXH32_round(v4, XXH_readLE32(p, endian)); p+=4;
|
||||
v1 = XXH32_round(v1, XXH_readLE32(p)); p+=4;
|
||||
v2 = XXH32_round(v2, XXH_readLE32(p)); p+=4;
|
||||
v3 = XXH32_round(v3, XXH_readLE32(p)); p+=4;
|
||||
v4 = XXH32_round(v4, XXH_readLE32(p)); p+=4;
|
||||
} while (p<=limit);
|
||||
|
||||
state->v1 = v1;
|
||||
|
|
@ -512,19 +596,7 @@ XXH32_update_endian(XXH32_state_t* state, const void* input, size_t len, XXH_end
|
|||
}
|
||||
|
||||
|
||||
XXH_PUBLIC_API XXH_errorcode XXH32_update (XXH32_state_t* state_in, const void* input, size_t len)
|
||||
{
|
||||
XXH_endianess endian_detected = (XXH_endianess)XXH_CPU_LITTLE_ENDIAN;
|
||||
|
||||
if ((endian_detected==XXH_littleEndian) || XXH_FORCE_NATIVE_FORMAT)
|
||||
return XXH32_update_endian(state_in, input, len, XXH_littleEndian);
|
||||
else
|
||||
return XXH32_update_endian(state_in, input, len, XXH_bigEndian);
|
||||
}
|
||||
|
||||
|
||||
FORCE_INLINE U32
|
||||
XXH32_digest_endian (const XXH32_state_t* state, XXH_endianess endian)
|
||||
XXH_PUBLIC_API unsigned int XXH32_digest (const XXH32_state_t* state)
|
||||
{
|
||||
U32 h32;
|
||||
|
||||
|
|
@ -539,18 +611,7 @@ XXH32_digest_endian (const XXH32_state_t* state, XXH_endianess endian)
|
|||
|
||||
h32 += state->total_len_32;
|
||||
|
||||
return XXH32_finalize(h32, state->mem32, state->memsize, endian, XXH_aligned);
|
||||
}
|
||||
|
||||
|
||||
XXH_PUBLIC_API unsigned int XXH32_digest (const XXH32_state_t* state_in)
|
||||
{
|
||||
XXH_endianess endian_detected = (XXH_endianess)XXH_CPU_LITTLE_ENDIAN;
|
||||
|
||||
if ((endian_detected==XXH_littleEndian) || XXH_FORCE_NATIVE_FORMAT)
|
||||
return XXH32_digest_endian(state_in, XXH_littleEndian);
|
||||
else
|
||||
return XXH32_digest_endian(state_in, XXH_bigEndian);
|
||||
return XXH32_finalize(h32, state->mem32, state->memsize, XXH_aligned);
|
||||
}
|
||||
|
||||
|
||||
|
|
@ -596,6 +657,31 @@ XXH_PUBLIC_API XXH32_hash_t XXH32_hashFromCanonical(const XXH32_canonical_t* src
|
|||
# endif
|
||||
#endif
|
||||
|
||||
/*! XXH_REROLL_XXH64:
|
||||
* Whether to reroll the XXH64_finalize() loop.
|
||||
*
|
||||
* Just like XXH32, we can unroll the XXH64_finalize() loop. This can be a performance gain
|
||||
* on 64-bit hosts, as only one jump is required.
|
||||
*
|
||||
* However, on 32-bit hosts, because arithmetic needs to be done with two 32-bit registers,
|
||||
* and 64-bit arithmetic needs to be simulated, it isn't beneficial to unroll. The code becomes
|
||||
* ridiculously large (the largest function in the binary on i386!), and rerolling it saves
|
||||
* anywhere from 3kB to 20kB. It is also slightly faster because it fits into cache better
|
||||
* and is more likely to be inlined by the compiler.
|
||||
*
|
||||
* If XXH_REROLL is defined, this is ignored and the loop is always rerolled. */
|
||||
#ifndef XXH_REROLL_XXH64
|
||||
# if (defined(__ILP32__) || defined(_ILP32)) /* ILP32 is often defined on 32-bit GCC family */ \
|
||||
|| !(defined(__x86_64__) || defined(_M_X64) || defined(_M_AMD64) /* x86-64 */ \
|
||||
|| defined(_M_ARM64) || defined(__aarch64__) || defined(__arm64__) /* aarch64 */ \
|
||||
|| defined(__PPC64__) || defined(__PPC64LE__) || defined(__ppc64__) || defined(__powerpc64__) /* ppc64 */ \
|
||||
|| defined(__mips64__) || defined(__mips64)) /* mips64 */ \
|
||||
|| (!defined(SIZE_MAX) || SIZE_MAX < ULLONG_MAX) /* check limits */
|
||||
# define XXH_REROLL_XXH64 1
|
||||
# else
|
||||
# define XXH_REROLL_XXH64 0
|
||||
# endif
|
||||
#endif /* !defined(XXH_REROLL_XXH64) */
|
||||
|
||||
#if (defined(XXH_FORCE_MEMORY_ACCESS) && (XXH_FORCE_MEMORY_ACCESS==2))
|
||||
|
||||
|
|
@ -642,17 +728,9 @@ static U64 XXH_swap64 (U64 x)
|
|||
}
|
||||
#endif
|
||||
|
||||
FORCE_INLINE U64 XXH_readLE64_align(const void* ptr, XXH_endianess endian, XXH_alignment align)
|
||||
XXH_FORCE_INLINE U64 XXH_readLE64(const void* ptr)
|
||||
{
|
||||
if (align==XXH_unaligned)
|
||||
return endian==XXH_littleEndian ? XXH_read64(ptr) : XXH_swap64(XXH_read64(ptr));
|
||||
else
|
||||
return endian==XXH_littleEndian ? *(const U64*)ptr : XXH_swap64(*(const U64*)ptr);
|
||||
}
|
||||
|
||||
FORCE_INLINE U64 XXH_readLE64(const void* ptr, XXH_endianess endian)
|
||||
{
|
||||
return XXH_readLE64_align(ptr, endian, XXH_unaligned);
|
||||
return XXH_CPU_LITTLE_ENDIAN ? XXH_read64(ptr) : XXH_swap64(XXH_read64(ptr));
|
||||
}
|
||||
|
||||
static U64 XXH_readBE64(const void* ptr)
|
||||
|
|
@ -660,14 +738,23 @@ static U64 XXH_readBE64(const void* ptr)
|
|||
return XXH_CPU_LITTLE_ENDIAN ? XXH_swap64(XXH_read64(ptr)) : XXH_read64(ptr);
|
||||
}
|
||||
|
||||
XXH_FORCE_INLINE U64
|
||||
XXH_readLE64_align(const void* ptr, XXH_alignment align)
|
||||
{
|
||||
if (align==XXH_unaligned)
|
||||
return XXH_readLE64(ptr);
|
||||
else
|
||||
return XXH_CPU_LITTLE_ENDIAN ? *(const U64*)ptr : XXH_swap64(*(const U64*)ptr);
|
||||
}
|
||||
|
||||
|
||||
/*====== xxh64 ======*/
|
||||
|
||||
static const U64 PRIME64_1 = 11400714785074694791ULL;
|
||||
static const U64 PRIME64_2 = 14029467366897019727ULL;
|
||||
static const U64 PRIME64_3 = 1609587929392839161ULL;
|
||||
static const U64 PRIME64_4 = 9650029242287828579ULL;
|
||||
static const U64 PRIME64_5 = 2870177450012600261ULL;
|
||||
static const U64 PRIME64_1 = 0x9E3779B185EBCA87ULL; /* 0b1001111000110111011110011011000110000101111010111100101010000111 */
|
||||
static const U64 PRIME64_2 = 0xC2B2AE3D27D4EB4FULL; /* 0b1100001010110010101011100011110100100111110101001110101101001111 */
|
||||
static const U64 PRIME64_3 = 0x165667B19E3779F9ULL; /* 0b0001011001010110011001111011000110011110001101110111100111111001 */
|
||||
static const U64 PRIME64_4 = 0x85EBCA77C2B2AE63ULL; /* 0b1000010111101011110010100111011111000010101100101010111001100011 */
|
||||
static const U64 PRIME64_5 = 0x27D4EB2F165667C5ULL; /* 0b0010011111010100111010110010111100010110010101100110011111000101 */
|
||||
|
||||
static U64 XXH64_round(U64 acc, U64 input)
|
||||
{
|
||||
|
|
@ -696,11 +783,10 @@ static U64 XXH64_avalanche(U64 h64)
|
|||
}
|
||||
|
||||
|
||||
#define XXH_get64bits(p) XXH_readLE64_align(p, endian, align)
|
||||
#define XXH_get64bits(p) XXH_readLE64_align(p, align)
|
||||
|
||||
static U64
|
||||
XXH64_finalize(U64 h64, const void* ptr, size_t len,
|
||||
XXH_endianess endian, XXH_alignment align)
|
||||
XXH64_finalize(U64 h64, const void* ptr, size_t len, XXH_alignment align)
|
||||
{
|
||||
const BYTE* p = (const BYTE*)ptr;
|
||||
|
||||
|
|
@ -720,96 +806,112 @@ XXH64_finalize(U64 h64, const void* ptr, size_t len,
|
|||
h64 = XXH_rotl64(h64,27) * PRIME64_1 + PRIME64_4; \
|
||||
}
|
||||
|
||||
switch(len&31) {
|
||||
case 24: PROCESS8_64;
|
||||
/* fallthrough */
|
||||
case 16: PROCESS8_64;
|
||||
/* fallthrough */
|
||||
case 8: PROCESS8_64;
|
||||
return XXH64_avalanche(h64);
|
||||
/* Rerolled version for 32-bit targets is faster and much smaller. */
|
||||
if (XXH_REROLL || XXH_REROLL_XXH64) {
|
||||
len &= 31;
|
||||
while (len >= 8) {
|
||||
PROCESS8_64;
|
||||
len -= 8;
|
||||
}
|
||||
if (len >= 4) {
|
||||
PROCESS4_64;
|
||||
len -= 4;
|
||||
}
|
||||
while (len > 0) {
|
||||
PROCESS1_64;
|
||||
--len;
|
||||
}
|
||||
return XXH64_avalanche(h64);
|
||||
} else {
|
||||
switch(len & 31) {
|
||||
case 24: PROCESS8_64;
|
||||
/* fallthrough */
|
||||
case 16: PROCESS8_64;
|
||||
/* fallthrough */
|
||||
case 8: PROCESS8_64;
|
||||
return XXH64_avalanche(h64);
|
||||
|
||||
case 28: PROCESS8_64;
|
||||
/* fallthrough */
|
||||
case 20: PROCESS8_64;
|
||||
/* fallthrough */
|
||||
case 12: PROCESS8_64;
|
||||
/* fallthrough */
|
||||
case 4: PROCESS4_64;
|
||||
return XXH64_avalanche(h64);
|
||||
case 28: PROCESS8_64;
|
||||
/* fallthrough */
|
||||
case 20: PROCESS8_64;
|
||||
/* fallthrough */
|
||||
case 12: PROCESS8_64;
|
||||
/* fallthrough */
|
||||
case 4: PROCESS4_64;
|
||||
return XXH64_avalanche(h64);
|
||||
|
||||
case 25: PROCESS8_64;
|
||||
/* fallthrough */
|
||||
case 17: PROCESS8_64;
|
||||
/* fallthrough */
|
||||
case 9: PROCESS8_64;
|
||||
PROCESS1_64;
|
||||
return XXH64_avalanche(h64);
|
||||
case 25: PROCESS8_64;
|
||||
/* fallthrough */
|
||||
case 17: PROCESS8_64;
|
||||
/* fallthrough */
|
||||
case 9: PROCESS8_64;
|
||||
PROCESS1_64;
|
||||
return XXH64_avalanche(h64);
|
||||
|
||||
case 29: PROCESS8_64;
|
||||
/* fallthrough */
|
||||
case 21: PROCESS8_64;
|
||||
/* fallthrough */
|
||||
case 13: PROCESS8_64;
|
||||
/* fallthrough */
|
||||
case 5: PROCESS4_64;
|
||||
PROCESS1_64;
|
||||
return XXH64_avalanche(h64);
|
||||
case 29: PROCESS8_64;
|
||||
/* fallthrough */
|
||||
case 21: PROCESS8_64;
|
||||
/* fallthrough */
|
||||
case 13: PROCESS8_64;
|
||||
/* fallthrough */
|
||||
case 5: PROCESS4_64;
|
||||
PROCESS1_64;
|
||||
return XXH64_avalanche(h64);
|
||||
|
||||
case 26: PROCESS8_64;
|
||||
/* fallthrough */
|
||||
case 18: PROCESS8_64;
|
||||
/* fallthrough */
|
||||
case 10: PROCESS8_64;
|
||||
PROCESS1_64;
|
||||
PROCESS1_64;
|
||||
return XXH64_avalanche(h64);
|
||||
case 26: PROCESS8_64;
|
||||
/* fallthrough */
|
||||
case 18: PROCESS8_64;
|
||||
/* fallthrough */
|
||||
case 10: PROCESS8_64;
|
||||
PROCESS1_64;
|
||||
PROCESS1_64;
|
||||
return XXH64_avalanche(h64);
|
||||
|
||||
case 30: PROCESS8_64;
|
||||
/* fallthrough */
|
||||
case 22: PROCESS8_64;
|
||||
/* fallthrough */
|
||||
case 14: PROCESS8_64;
|
||||
/* fallthrough */
|
||||
case 6: PROCESS4_64;
|
||||
PROCESS1_64;
|
||||
PROCESS1_64;
|
||||
return XXH64_avalanche(h64);
|
||||
case 30: PROCESS8_64;
|
||||
/* fallthrough */
|
||||
case 22: PROCESS8_64;
|
||||
/* fallthrough */
|
||||
case 14: PROCESS8_64;
|
||||
/* fallthrough */
|
||||
case 6: PROCESS4_64;
|
||||
PROCESS1_64;
|
||||
PROCESS1_64;
|
||||
return XXH64_avalanche(h64);
|
||||
|
||||
case 27: PROCESS8_64;
|
||||
/* fallthrough */
|
||||
case 19: PROCESS8_64;
|
||||
/* fallthrough */
|
||||
case 11: PROCESS8_64;
|
||||
PROCESS1_64;
|
||||
PROCESS1_64;
|
||||
PROCESS1_64;
|
||||
return XXH64_avalanche(h64);
|
||||
case 27: PROCESS8_64;
|
||||
/* fallthrough */
|
||||
case 19: PROCESS8_64;
|
||||
/* fallthrough */
|
||||
case 11: PROCESS8_64;
|
||||
PROCESS1_64;
|
||||
PROCESS1_64;
|
||||
PROCESS1_64;
|
||||
return XXH64_avalanche(h64);
|
||||
|
||||
case 31: PROCESS8_64;
|
||||
/* fallthrough */
|
||||
case 23: PROCESS8_64;
|
||||
/* fallthrough */
|
||||
case 15: PROCESS8_64;
|
||||
/* fallthrough */
|
||||
case 7: PROCESS4_64;
|
||||
/* fallthrough */
|
||||
case 3: PROCESS1_64;
|
||||
/* fallthrough */
|
||||
case 2: PROCESS1_64;
|
||||
/* fallthrough */
|
||||
case 1: PROCESS1_64;
|
||||
/* fallthrough */
|
||||
case 0: return XXH64_avalanche(h64);
|
||||
case 31: PROCESS8_64;
|
||||
/* fallthrough */
|
||||
case 23: PROCESS8_64;
|
||||
/* fallthrough */
|
||||
case 15: PROCESS8_64;
|
||||
/* fallthrough */
|
||||
case 7: PROCESS4_64;
|
||||
/* fallthrough */
|
||||
case 3: PROCESS1_64;
|
||||
/* fallthrough */
|
||||
case 2: PROCESS1_64;
|
||||
/* fallthrough */
|
||||
case 1: PROCESS1_64;
|
||||
/* fallthrough */
|
||||
case 0: return XXH64_avalanche(h64);
|
||||
}
|
||||
}
|
||||
|
||||
/* impossible to reach */
|
||||
assert(0);
|
||||
XXH_ASSERT(0);
|
||||
return 0; /* unreachable, but some compilers complain without it */
|
||||
}
|
||||
|
||||
FORCE_INLINE U64
|
||||
XXH64_endian_align(const void* input, size_t len, U64 seed,
|
||||
XXH_endianess endian, XXH_alignment align)
|
||||
XXH_FORCE_INLINE U64
|
||||
XXH64_endian_align(const void* input, size_t len, U64 seed, XXH_alignment align)
|
||||
{
|
||||
const BYTE* p = (const BYTE*)input;
|
||||
const BYTE* bEnd = p + len;
|
||||
|
|
@ -848,11 +950,11 @@ XXH64_endian_align(const void* input, size_t len, U64 seed,
|
|||
|
||||
h64 += (U64) len;
|
||||
|
||||
return XXH64_finalize(h64, p, len, endian, align);
|
||||
return XXH64_finalize(h64, p, len, align);
|
||||
}
|
||||
|
||||
|
||||
XXH_PUBLIC_API unsigned long long XXH64 (const void* input, size_t len, unsigned long long seed)
|
||||
XXH_PUBLIC_API XXH64_hash_t XXH64 (const void* input, size_t len, unsigned long long seed)
|
||||
{
|
||||
#if 0
|
||||
/* Simple version, good for code maintenance, but unfortunately slow for small inputs */
|
||||
|
|
@ -860,21 +962,16 @@ XXH_PUBLIC_API unsigned long long XXH64 (const void* input, size_t len, unsigned
|
|||
XXH64_reset(&state, seed);
|
||||
XXH64_update(&state, input, len);
|
||||
return XXH64_digest(&state);
|
||||
|
||||
#else
|
||||
XXH_endianess endian_detected = (XXH_endianess)XXH_CPU_LITTLE_ENDIAN;
|
||||
|
||||
if (XXH_FORCE_ALIGN_CHECK) {
|
||||
if ((((size_t)input) & 7)==0) { /* Input is aligned, let's leverage the speed advantage */
|
||||
if ((endian_detected==XXH_littleEndian) || XXH_FORCE_NATIVE_FORMAT)
|
||||
return XXH64_endian_align(input, len, seed, XXH_littleEndian, XXH_aligned);
|
||||
else
|
||||
return XXH64_endian_align(input, len, seed, XXH_bigEndian, XXH_aligned);
|
||||
return XXH64_endian_align(input, len, seed, XXH_aligned);
|
||||
} }
|
||||
|
||||
if ((endian_detected==XXH_littleEndian) || XXH_FORCE_NATIVE_FORMAT)
|
||||
return XXH64_endian_align(input, len, seed, XXH_littleEndian, XXH_unaligned);
|
||||
else
|
||||
return XXH64_endian_align(input, len, seed, XXH_bigEndian, XXH_unaligned);
|
||||
return XXH64_endian_align(input, len, seed, XXH_unaligned);
|
||||
|
||||
#endif
|
||||
}
|
||||
|
||||
|
|
@ -903,13 +1000,13 @@ XXH_PUBLIC_API XXH_errorcode XXH64_reset(XXH64_state_t* statePtr, unsigned long
|
|||
state.v2 = seed + PRIME64_2;
|
||||
state.v3 = seed + 0;
|
||||
state.v4 = seed - PRIME64_1;
|
||||
/* do not write into reserved, planned to be removed in a future version */
|
||||
/* do not write into reserved, might be removed in a future version */
|
||||
memcpy(statePtr, &state, sizeof(state) - sizeof(state.reserved));
|
||||
return XXH_OK;
|
||||
}
|
||||
|
||||
FORCE_INLINE XXH_errorcode
|
||||
XXH64_update_endian (XXH64_state_t* state, const void* input, size_t len, XXH_endianess endian)
|
||||
XXH_PUBLIC_API XXH_errorcode
|
||||
XXH64_update (XXH64_state_t* state, const void* input, size_t len)
|
||||
{
|
||||
if (input==NULL)
|
||||
#if defined(XXH_ACCEPT_NULL_INPUT_POINTER) && (XXH_ACCEPT_NULL_INPUT_POINTER>=1)
|
||||
|
|
@ -931,10 +1028,10 @@ XXH64_update_endian (XXH64_state_t* state, const void* input, size_t len, XXH_en
|
|||
|
||||
if (state->memsize) { /* tmp buffer is full */
|
||||
XXH_memcpy(((BYTE*)state->mem64) + state->memsize, input, 32-state->memsize);
|
||||
state->v1 = XXH64_round(state->v1, XXH_readLE64(state->mem64+0, endian));
|
||||
state->v2 = XXH64_round(state->v2, XXH_readLE64(state->mem64+1, endian));
|
||||
state->v3 = XXH64_round(state->v3, XXH_readLE64(state->mem64+2, endian));
|
||||
state->v4 = XXH64_round(state->v4, XXH_readLE64(state->mem64+3, endian));
|
||||
state->v1 = XXH64_round(state->v1, XXH_readLE64(state->mem64+0));
|
||||
state->v2 = XXH64_round(state->v2, XXH_readLE64(state->mem64+1));
|
||||
state->v3 = XXH64_round(state->v3, XXH_readLE64(state->mem64+2));
|
||||
state->v4 = XXH64_round(state->v4, XXH_readLE64(state->mem64+3));
|
||||
p += 32-state->memsize;
|
||||
state->memsize = 0;
|
||||
}
|
||||
|
|
@ -947,10 +1044,10 @@ XXH64_update_endian (XXH64_state_t* state, const void* input, size_t len, XXH_en
|
|||
U64 v4 = state->v4;
|
||||
|
||||
do {
|
||||
v1 = XXH64_round(v1, XXH_readLE64(p, endian)); p+=8;
|
||||
v2 = XXH64_round(v2, XXH_readLE64(p, endian)); p+=8;
|
||||
v3 = XXH64_round(v3, XXH_readLE64(p, endian)); p+=8;
|
||||
v4 = XXH64_round(v4, XXH_readLE64(p, endian)); p+=8;
|
||||
v1 = XXH64_round(v1, XXH_readLE64(p)); p+=8;
|
||||
v2 = XXH64_round(v2, XXH_readLE64(p)); p+=8;
|
||||
v3 = XXH64_round(v3, XXH_readLE64(p)); p+=8;
|
||||
v4 = XXH64_round(v4, XXH_readLE64(p)); p+=8;
|
||||
} while (p<=limit);
|
||||
|
||||
state->v1 = v1;
|
||||
|
|
@ -968,17 +1065,8 @@ XXH64_update_endian (XXH64_state_t* state, const void* input, size_t len, XXH_en
|
|||
return XXH_OK;
|
||||
}
|
||||
|
||||
XXH_PUBLIC_API XXH_errorcode XXH64_update (XXH64_state_t* state_in, const void* input, size_t len)
|
||||
{
|
||||
XXH_endianess endian_detected = (XXH_endianess)XXH_CPU_LITTLE_ENDIAN;
|
||||
|
||||
if ((endian_detected==XXH_littleEndian) || XXH_FORCE_NATIVE_FORMAT)
|
||||
return XXH64_update_endian(state_in, input, len, XXH_littleEndian);
|
||||
else
|
||||
return XXH64_update_endian(state_in, input, len, XXH_bigEndian);
|
||||
}
|
||||
|
||||
FORCE_INLINE U64 XXH64_digest_endian (const XXH64_state_t* state, XXH_endianess endian)
|
||||
XXH_PUBLIC_API XXH64_hash_t XXH64_digest (const XXH64_state_t* state)
|
||||
{
|
||||
U64 h64;
|
||||
|
||||
|
|
@ -999,17 +1087,7 @@ FORCE_INLINE U64 XXH64_digest_endian (const XXH64_state_t* state, XXH_endianess
|
|||
|
||||
h64 += (U64) state->total_len;
|
||||
|
||||
return XXH64_finalize(h64, state->mem64, (size_t)state->total_len, endian, XXH_aligned);
|
||||
}
|
||||
|
||||
XXH_PUBLIC_API unsigned long long XXH64_digest (const XXH64_state_t* state_in)
|
||||
{
|
||||
XXH_endianess endian_detected = (XXH_endianess)XXH_CPU_LITTLE_ENDIAN;
|
||||
|
||||
if ((endian_detected==XXH_littleEndian) || XXH_FORCE_NATIVE_FORMAT)
|
||||
return XXH64_digest_endian(state_in, XXH_littleEndian);
|
||||
else
|
||||
return XXH64_digest_endian(state_in, XXH_bigEndian);
|
||||
return XXH64_finalize(h64, state->mem64, (size_t)state->total_len, XXH_aligned);
|
||||
}
|
||||
|
||||
|
||||
|
|
@ -1027,4 +1105,14 @@ XXH_PUBLIC_API XXH64_hash_t XXH64_hashFromCanonical(const XXH64_canonical_t* src
|
|||
return XXH_readBE64(src);
|
||||
}
|
||||
|
||||
|
||||
|
||||
/* *********************************************************************
|
||||
* XXH3
|
||||
* New generation hash designed for speed on small keys and vectorization
|
||||
************************************************************************ */
|
||||
|
||||
#include "xxh3.h"
|
||||
|
||||
|
||||
#endif /* XXH_NO_LONG_LONG */
|
||||
|
|
|
|||
|
|
@ -83,14 +83,16 @@ typedef enum { XXH_OK=0, XXH_ERROR } XXH_errorcode;
|
|||
* API modifier
|
||||
******************************/
|
||||
/** XXH_INLINE_ALL (and XXH_PRIVATE_API)
|
||||
* This is useful to include xxhash functions in `static` mode
|
||||
* This build macro includes xxhash functions in `static` mode
|
||||
* in order to inline them, and remove their symbol from the public list.
|
||||
* Inlining can offer dramatic performance improvement on small keys.
|
||||
* Inlining offers great performance improvement on small keys,
|
||||
* and dramatic ones when length is expressed as a compile-time constant.
|
||||
* See https://fastcompression.blogspot.com/2018/03/xxhash-for-small-keys-impressive-power.html .
|
||||
* Methodology :
|
||||
* #define XXH_INLINE_ALL
|
||||
* #include "xxhash.h"
|
||||
* `xxhash.c` is automatically included.
|
||||
* It's not useful to compile and link it as a separate module.
|
||||
* It's not useful to compile and link it as a separate object.
|
||||
*/
|
||||
#if defined(XXH_INLINE_ALL) || defined(XXH_PRIVATE_API)
|
||||
# ifndef XXH_STATIC_LINKING_ONLY
|
||||
|
|
@ -107,7 +109,15 @@ typedef enum { XXH_OK=0, XXH_ERROR } XXH_errorcode;
|
|||
# define XXH_PUBLIC_API static
|
||||
# endif
|
||||
#else
|
||||
# define XXH_PUBLIC_API /* do nothing */
|
||||
# if defined(WIN32) && defined(_MSC_VER) && (defined(XXH_IMPORT) || defined(XXH_EXPORT))
|
||||
# ifdef XXH_EXPORT
|
||||
# define XXH_PUBLIC_API __declspec(dllexport)
|
||||
# elif XXH_IMPORT
|
||||
# define XXH_PUBLIC_API __declspec(dllimport)
|
||||
# endif
|
||||
# else
|
||||
# define XXH_PUBLIC_API /* do nothing */
|
||||
# endif
|
||||
#endif /* XXH_INLINE_ALL || XXH_PRIVATE_API */
|
||||
|
||||
/*! XXH_NAMESPACE, aka Namespace Emulation :
|
||||
|
|
@ -150,8 +160,8 @@ typedef enum { XXH_OK=0, XXH_ERROR } XXH_errorcode;
|
|||
* Version
|
||||
***************************************/
|
||||
#define XXH_VERSION_MAJOR 0
|
||||
#define XXH_VERSION_MINOR 6
|
||||
#define XXH_VERSION_RELEASE 5
|
||||
#define XXH_VERSION_MINOR 7
|
||||
#define XXH_VERSION_RELEASE 1
|
||||
#define XXH_VERSION_NUMBER (XXH_VERSION_MAJOR *100*100 + XXH_VERSION_MINOR *100 + XXH_VERSION_RELEASE)
|
||||
XXH_PUBLIC_API unsigned XXH_versionNumber (void);
|
||||
|
||||
|
|
@ -159,7 +169,14 @@ XXH_PUBLIC_API unsigned XXH_versionNumber (void);
|
|||
/*-**********************************************************************
|
||||
* 32-bit hash
|
||||
************************************************************************/
|
||||
typedef unsigned int XXH32_hash_t;
|
||||
#if !defined (__VMS) \
|
||||
&& (defined (__cplusplus) \
|
||||
|| (defined (__STDC_VERSION__) && (__STDC_VERSION__ >= 199901L) /* C99 */) )
|
||||
# include <stdint.h>
|
||||
typedef uint32_t XXH32_hash_t;
|
||||
#else
|
||||
typedef unsigned int XXH32_hash_t;
|
||||
#endif
|
||||
|
||||
/*! XXH32() :
|
||||
Calculate the 32-bit hash of sequence "length" bytes stored at memory address "input".
|
||||
|
|
@ -216,7 +233,14 @@ XXH_PUBLIC_API XXH32_hash_t XXH32_hashFromCanonical(const XXH32_canonical_t* src
|
|||
/*-**********************************************************************
|
||||
* 64-bit hash
|
||||
************************************************************************/
|
||||
typedef unsigned long long XXH64_hash_t;
|
||||
#if !defined (__VMS) \
|
||||
&& (defined (__cplusplus) \
|
||||
|| (defined (__STDC_VERSION__) && (__STDC_VERSION__ >= 199901L) /* C99 */) )
|
||||
# include <stdint.h>
|
||||
typedef uint64_t XXH64_hash_t;
|
||||
#else
|
||||
typedef unsigned long long XXH64_hash_t;
|
||||
#endif
|
||||
|
||||
/*! XXH64() :
|
||||
Calculate the 64-bit hash of sequence of length "len" stored at memory address "input".
|
||||
|
|
@ -239,6 +263,8 @@ XXH_PUBLIC_API XXH64_hash_t XXH64_digest (const XXH64_state_t* statePtr);
|
|||
typedef struct { unsigned char digest[8]; } XXH64_canonical_t;
|
||||
XXH_PUBLIC_API void XXH64_canonicalFromHash(XXH64_canonical_t* dst, XXH64_hash_t hash);
|
||||
XXH_PUBLIC_API XXH64_hash_t XXH64_hashFromCanonical(const XXH64_canonical_t* src);
|
||||
|
||||
|
||||
#endif /* XXH_NO_LONG_LONG */
|
||||
|
||||
|
||||
|
|
@ -256,68 +282,258 @@ XXH_PUBLIC_API XXH64_hash_t XXH64_hashFromCanonical(const XXH64_canonical_t* src
|
|||
* static allocation of XXH state, on stack or in a struct for example.
|
||||
* Never **ever** use members directly. */
|
||||
|
||||
#if !defined (__VMS) \
|
||||
&& (defined (__cplusplus) \
|
||||
|| (defined (__STDC_VERSION__) && (__STDC_VERSION__ >= 199901L) /* C99 */) )
|
||||
# include <stdint.h>
|
||||
|
||||
struct XXH32_state_s {
|
||||
uint32_t total_len_32;
|
||||
uint32_t large_len;
|
||||
uint32_t v1;
|
||||
uint32_t v2;
|
||||
uint32_t v3;
|
||||
uint32_t v4;
|
||||
uint32_t mem32[4];
|
||||
uint32_t memsize;
|
||||
uint32_t reserved; /* never read nor write, might be removed in a future version */
|
||||
XXH32_hash_t total_len_32;
|
||||
XXH32_hash_t large_len;
|
||||
XXH32_hash_t v1;
|
||||
XXH32_hash_t v2;
|
||||
XXH32_hash_t v3;
|
||||
XXH32_hash_t v4;
|
||||
XXH32_hash_t mem32[4];
|
||||
XXH32_hash_t memsize;
|
||||
XXH32_hash_t reserved; /* never read nor write, might be removed in a future version */
|
||||
}; /* typedef'd to XXH32_state_t */
|
||||
|
||||
#ifndef XXH_NO_LONG_LONG /* remove 64-bit support */
|
||||
struct XXH64_state_s {
|
||||
uint64_t total_len;
|
||||
uint64_t v1;
|
||||
uint64_t v2;
|
||||
uint64_t v3;
|
||||
uint64_t v4;
|
||||
uint64_t mem64[4];
|
||||
uint32_t memsize;
|
||||
uint32_t reserved[2]; /* never read nor write, might be removed in a future version */
|
||||
XXH64_hash_t total_len;
|
||||
XXH64_hash_t v1;
|
||||
XXH64_hash_t v2;
|
||||
XXH64_hash_t v3;
|
||||
XXH64_hash_t v4;
|
||||
XXH64_hash_t mem64[4];
|
||||
XXH32_hash_t memsize;
|
||||
XXH32_hash_t reserved[2]; /* never read nor write, might be removed in a future version */
|
||||
}; /* typedef'd to XXH64_state_t */
|
||||
|
||||
# else
|
||||
|
||||
struct XXH32_state_s {
|
||||
unsigned total_len_32;
|
||||
unsigned large_len;
|
||||
unsigned v1;
|
||||
unsigned v2;
|
||||
unsigned v3;
|
||||
unsigned v4;
|
||||
unsigned mem32[4];
|
||||
unsigned memsize;
|
||||
unsigned reserved; /* never read nor write, might be removed in a future version */
|
||||
}; /* typedef'd to XXH32_state_t */
|
||||
|
||||
# ifndef XXH_NO_LONG_LONG /* remove 64-bit support */
|
||||
struct XXH64_state_s {
|
||||
unsigned long long total_len;
|
||||
unsigned long long v1;
|
||||
unsigned long long v2;
|
||||
unsigned long long v3;
|
||||
unsigned long long v4;
|
||||
unsigned long long mem64[4];
|
||||
unsigned memsize;
|
||||
unsigned reserved[2]; /* never read nor write, might be removed in a future version */
|
||||
}; /* typedef'd to XXH64_state_t */
|
||||
# endif
|
||||
|
||||
# endif
|
||||
#endif /* XXH_NO_LONG_LONG */
|
||||
|
||||
|
||||
/*-**********************************************************************
|
||||
* XXH3
|
||||
* New experimental hash
|
||||
************************************************************************/
|
||||
#ifndef XXH_NO_LONG_LONG
|
||||
|
||||
|
||||
/* ============================================
|
||||
* XXH3 is a new hash algorithm,
|
||||
* featuring improved speed performance for both small and large inputs.
|
||||
* See full speed analysis at : http://fastcompression.blogspot.com/2019/03/presenting-xxh3.html
|
||||
* In general, expect XXH3 to run about ~2x faster on large inputs,
|
||||
* and >3x faster on small ones, though exact differences depend on platform.
|
||||
*
|
||||
* The algorithm is portable, will generate the same hash on all platforms.
|
||||
* It benefits greatly from vectorization units, but does not require it.
|
||||
*
|
||||
* XXH3 offers 2 variants, _64bits and _128bits.
|
||||
* When only 64 bits are needed, prefer calling the _64bits variant :
|
||||
* it reduces the amount of mixing, resulting in faster speed on small inputs.
|
||||
* It's also generally simpler to manipulate a scalar return type than a struct.
|
||||
*
|
||||
* The XXH3 algorithm is still considered experimental.
|
||||
* Produced results can still change between versions.
|
||||
* For example, results produced by v0.7.1 are not comparable with results from v0.7.0 .
|
||||
* It's nonetheless possible to use XXH3 for ephemeral data (local sessions),
|
||||
* but avoid storing values in long-term storage for later re-use.
|
||||
*
|
||||
* The API supports one-shot hashing, streaming mode, and custom secrets.
|
||||
*
|
||||
* There are still a number of opened questions that community can influence during the experimental period.
|
||||
* I'm trying to list a few of them below, though don't consider this list as complete.
|
||||
*
|
||||
* - 128-bits output type : currently defined as a structure of two 64-bits fields.
|
||||
* That's because 128-bit values do not exist in C standard.
|
||||
* Note that it means that, at byte level, result is not identical depending on endianess.
|
||||
* However, at field level, they are identical on all platforms.
|
||||
* The canonical representation solves the issue of identical byte-level representation across platforms,
|
||||
* which is necessary for serialization.
|
||||
* Would there be a better representation for a 128-bit hash result ?
|
||||
* Are the names of the inner 64-bit fields important ? Should they be changed ?
|
||||
*
|
||||
* - Seed type for 128-bits variant : currently, it's a single 64-bit value, like the 64-bit variant.
|
||||
* It could be argued that it's more logical to offer a 128-bit seed input parameter for a 128-bit hash.
|
||||
* But 128-bit seed is more difficult to use, since it requires to pass a structure instead of a scalar value.
|
||||
* Such a variant could either replace current one, or become an additional one.
|
||||
* Farmhash, for example, offers both variants (the 128-bits seed variant is called `doubleSeed`).
|
||||
* If both 64-bit and 128-bit seeds are possible, which variant should be called XXH128 ?
|
||||
*
|
||||
* - Result for len==0 : Currently, the result of hashing a zero-length input is `0`.
|
||||
* It seems okay as a return value when using all "default" secret and seed (it used to be a request for XXH32/XXH64).
|
||||
* But is it still fine to return `0` when secret or seed are non-default ?
|
||||
* Are there use cases which could depend on generating a different hash result for zero-length input when the secret is different ?
|
||||
*/
|
||||
|
||||
#ifdef XXH_NAMESPACE
|
||||
# define XXH3_64bits XXH_NAME2(XXH_NAMESPACE, XXH3_64bits)
|
||||
# define XXH3_64bits_withSecret XXH_NAME2(XXH_NAMESPACE, XXH3_64bits_withSecret)
|
||||
# define XXH3_64bits_withSeed XXH_NAME2(XXH_NAMESPACE, XXH3_64bits_withSeed)
|
||||
|
||||
# define XXH3_createState XXH_NAME2(XXH_NAMESPACE, XXH3_createState)
|
||||
# define XXH3_freeState XXH_NAME2(XXH_NAMESPACE, XXH3_freeState)
|
||||
# define XXH3_copyState XXH_NAME2(XXH_NAMESPACE, XXH3_copyState)
|
||||
|
||||
# define XXH3_64bits_reset XXH_NAME2(XXH_NAMESPACE, XXH3_64bits_reset)
|
||||
# define XXH3_64bits_reset_withSeed XXH_NAME2(XXH_NAMESPACE, XXH3_64bits_reset_withSeed)
|
||||
# define XXH3_64bits_reset_withSecret XXH_NAME2(XXH_NAMESPACE, XXH3_64bits_reset_withSecret)
|
||||
# define XXH3_64bits_update XXH_NAME2(XXH_NAMESPACE, XXH3_64bits_update)
|
||||
# define XXH3_64bits_digest XXH_NAME2(XXH_NAMESPACE, XXH3_64bits_digest)
|
||||
#endif
|
||||
|
||||
/* XXH3_64bits() :
|
||||
* default 64-bit variant, using default secret and default seed of 0.
|
||||
* It's the fastest variant. */
|
||||
XXH_PUBLIC_API XXH64_hash_t XXH3_64bits(const void* data, size_t len);
|
||||
|
||||
/* XXH3_64bits_withSecret() :
|
||||
* It's possible to provide any blob of bytes as a "secret" to generate the hash.
|
||||
* This makes it more difficult for an external actor to prepare an intentional collision.
|
||||
* The secret *must* be large enough (>= XXH3_SECRET_SIZE_MIN).
|
||||
* It should consist of random bytes.
|
||||
* Avoid repeating same character, or sequences of bytes,
|
||||
* and especially avoid swathes of \0.
|
||||
* Failure to respect these conditions will result in a poor quality hash.
|
||||
*/
|
||||
#define XXH3_SECRET_SIZE_MIN 136
|
||||
XXH_PUBLIC_API XXH64_hash_t XXH3_64bits_withSecret(const void* data, size_t len, const void* secret, size_t secretSize);
|
||||
|
||||
/* XXH3_64bits_withSeed() :
|
||||
* This variant generates on the fly a custom secret,
|
||||
* based on the default secret, altered using the `seed` value.
|
||||
* While this operation is decently fast, note that it's not completely free.
|
||||
* note : seed==0 produces same results as XXH3_64bits() */
|
||||
XXH_PUBLIC_API XXH64_hash_t XXH3_64bits_withSeed(const void* data, size_t len, XXH64_hash_t seed);
|
||||
|
||||
|
||||
/* streaming 64-bit */
|
||||
|
||||
#if defined (__STDC_VERSION__) && (__STDC_VERSION__ >= 201112L) /* C11+ */
|
||||
# include <stdalign.h>
|
||||
# define XXH_ALIGN(n) alignas(n)
|
||||
#elif defined(__GNUC__)
|
||||
# define XXH_ALIGN(n) __attribute__ ((aligned(n)))
|
||||
#elif defined(_MSC_VER)
|
||||
# define XXH_ALIGN(n) __declspec(align(n))
|
||||
#else
|
||||
# define XXH_ALIGN(n) /* disabled */
|
||||
#endif
|
||||
|
||||
typedef struct XXH3_state_s XXH3_state_t;
|
||||
|
||||
#define XXH3_SECRET_DEFAULT_SIZE 192 /* minimum XXH3_SECRET_SIZE_MIN */
|
||||
#define XXH3_INTERNALBUFFER_SIZE 256
|
||||
struct XXH3_state_s {
|
||||
XXH_ALIGN(64) XXH64_hash_t acc[8];
|
||||
XXH_ALIGN(64) char customSecret[XXH3_SECRET_DEFAULT_SIZE]; /* used to store a custom secret generated from the seed. Makes state larger. Design might change */
|
||||
XXH_ALIGN(64) char buffer[XXH3_INTERNALBUFFER_SIZE];
|
||||
const void* secret;
|
||||
XXH32_hash_t bufferedSize;
|
||||
XXH32_hash_t nbStripesPerBlock;
|
||||
XXH32_hash_t nbStripesSoFar;
|
||||
XXH32_hash_t reserved32;
|
||||
XXH32_hash_t reserved32_2;
|
||||
XXH32_hash_t secretLimit;
|
||||
XXH64_hash_t totalLen;
|
||||
XXH64_hash_t seed;
|
||||
XXH64_hash_t reserved64;
|
||||
}; /* typedef'd to XXH3_state_t */
|
||||
|
||||
/* Streaming requires state maintenance.
|
||||
* This operation costs memory and cpu.
|
||||
* As a consequence, streaming is slower than one-shot hashing.
|
||||
* For better performance, prefer using one-shot functions whenever possible. */
|
||||
|
||||
XXH_PUBLIC_API XXH3_state_t* XXH3_createState(void);
|
||||
XXH_PUBLIC_API XXH_errorcode XXH3_freeState(XXH3_state_t* statePtr);
|
||||
XXH_PUBLIC_API void XXH3_copyState(XXH3_state_t* dst_state, const XXH3_state_t* src_state);
|
||||
|
||||
|
||||
/* XXH3_64bits_reset() :
|
||||
* initialize with default parameters.
|
||||
* result will be equivalent to `XXH3_64bits()`. */
|
||||
XXH_PUBLIC_API XXH_errorcode XXH3_64bits_reset(XXH3_state_t* statePtr);
|
||||
/* XXH3_64bits_reset_withSeed() :
|
||||
* generate a custom secret from `seed`, and store it into state.
|
||||
* digest will be equivalent to `XXH3_64bits_withSeed()`. */
|
||||
XXH_PUBLIC_API XXH_errorcode XXH3_64bits_reset_withSeed(XXH3_state_t* statePtr, XXH64_hash_t seed);
|
||||
/* XXH3_64bits_reset_withSecret() :
|
||||
* `secret` is referenced, and must outlive the hash streaming session.
|
||||
* secretSize must be >= XXH3_SECRET_SIZE_MIN.
|
||||
*/
|
||||
XXH_PUBLIC_API XXH_errorcode XXH3_64bits_reset_withSecret(XXH3_state_t* statePtr, const void* secret, size_t secretSize);
|
||||
|
||||
XXH_PUBLIC_API XXH_errorcode XXH3_64bits_update (XXH3_state_t* statePtr, const void* input, size_t length);
|
||||
XXH_PUBLIC_API XXH64_hash_t XXH3_64bits_digest (const XXH3_state_t* statePtr);
|
||||
|
||||
|
||||
/* 128-bit */
|
||||
|
||||
#ifdef XXH_NAMESPACE
|
||||
# define XXH128 XXH_NAME2(XXH_NAMESPACE, XXH128)
|
||||
# define XXH3_128bits XXH_NAME2(XXH_NAMESPACE, XXH3_128bits)
|
||||
# define XXH3_128bits_withSeed XXH_NAME2(XXH_NAMESPACE, XXH3_128bits_withSeed)
|
||||
# define XXH3_128bits_withSecret XXH_NAME2(XXH_NAMESPACE, XXH3_128bits_withSecret)
|
||||
|
||||
# define XXH3_128bits_reset XXH_NAME2(XXH_NAMESPACE, XXH3_128bits_reset)
|
||||
# define XXH3_128bits_reset_withSeed XXH_NAME2(XXH_NAMESPACE, XXH3_128bits_reset_withSeed)
|
||||
# define XXH3_128bits_reset_withSecret XXH_NAME2(XXH_NAMESPACE, XXH3_128bits_reset_withSecret)
|
||||
# define XXH3_128bits_update XXH_NAME2(XXH_NAMESPACE, XXH3_128bits_update)
|
||||
# define XXH3_128bits_digest XXH_NAME2(XXH_NAMESPACE, XXH3_128bits_digest)
|
||||
|
||||
# define XXH128_isEqual XXH_NAME2(XXH_NAMESPACE, XXH128_isEqual)
|
||||
# define XXH128_cmp XXH_NAME2(XXH_NAMESPACE, XXH128_cmp)
|
||||
# define XXH128_canonicalFromHash XXH_NAME2(XXH_NAMESPACE, XXH128_canonicalFromHash)
|
||||
# define XXH128_hashFromCanonical XXH_NAME2(XXH_NAMESPACE, XXH128_hashFromCanonical)
|
||||
#endif
|
||||
|
||||
typedef struct {
|
||||
XXH64_hash_t low64;
|
||||
XXH64_hash_t high64;
|
||||
} XXH128_hash_t;
|
||||
|
||||
XXH_PUBLIC_API XXH128_hash_t XXH128(const void* data, size_t len, XXH64_hash_t seed);
|
||||
XXH_PUBLIC_API XXH128_hash_t XXH3_128bits(const void* data, size_t len);
|
||||
XXH_PUBLIC_API XXH128_hash_t XXH3_128bits_withSeed(const void* data, size_t len, XXH64_hash_t seed); /* == XXH128() */
|
||||
XXH_PUBLIC_API XXH128_hash_t XXH3_128bits_withSecret(const void* data, size_t len, const void* secret, size_t secretSize);
|
||||
|
||||
XXH_PUBLIC_API XXH_errorcode XXH3_128bits_reset(XXH3_state_t* statePtr);
|
||||
XXH_PUBLIC_API XXH_errorcode XXH3_128bits_reset_withSeed(XXH3_state_t* statePtr, XXH64_hash_t seed);
|
||||
XXH_PUBLIC_API XXH_errorcode XXH3_128bits_reset_withSecret(XXH3_state_t* statePtr, const void* secret, size_t secretSize);
|
||||
|
||||
XXH_PUBLIC_API XXH_errorcode XXH3_128bits_update (XXH3_state_t* statePtr, const void* input, size_t length);
|
||||
XXH_PUBLIC_API XXH128_hash_t XXH3_128bits_digest (const XXH3_state_t* statePtr);
|
||||
|
||||
|
||||
/* Note : for better performance, following functions should be inlined,
|
||||
* using XXH_INLINE_ALL */
|
||||
|
||||
/* return : 1 is equal, 0 if different */
|
||||
XXH_PUBLIC_API int XXH128_isEqual(XXH128_hash_t h1, XXH128_hash_t h2);
|
||||
|
||||
/* This comparator is compatible with stdlib's qsort().
|
||||
* return : >0 if *h128_1 > *h128_2
|
||||
* <0 if *h128_1 < *h128_2
|
||||
* =0 if *h128_1 == *h128_2 */
|
||||
XXH_PUBLIC_API int XXH128_cmp(const void* h128_1, const void* h128_2);
|
||||
|
||||
|
||||
/*====== Canonical representation ======*/
|
||||
typedef struct { unsigned char digest[16]; } XXH128_canonical_t;
|
||||
XXH_PUBLIC_API void XXH128_canonicalFromHash(XXH128_canonical_t* dst, XXH128_hash_t hash);
|
||||
XXH_PUBLIC_API XXH128_hash_t XXH128_hashFromCanonical(const XXH128_canonical_t* src);
|
||||
|
||||
|
||||
#endif /* XXH_NO_LONG_LONG */
|
||||
|
||||
|
||||
/*-**********************************************************************
|
||||
* XXH_INLINE_ALL
|
||||
************************************************************************/
|
||||
#if defined(XXH_INLINE_ALL) || defined(XXH_PRIVATE_API)
|
||||
# include "xxhash.c" /* include xxhash function bodies as `static`, for inlining */
|
||||
#endif
|
||||
|
||||
|
||||
|
||||
#endif /* XXH_STATIC_LINKING_ONLY */
|
||||
|
||||
|
||||
|
|
|
|||
|
|
@ -0,0 +1,150 @@
|
|||
.
|
||||
.TH "XXHSUM" "1" "July 2019" "xxhsum 0.7.1" "User Commands"
|
||||
.
|
||||
.SH "NAME"
|
||||
\fBxxhsum\fR \- print or check xxHash non\-cryptographic checksums
|
||||
.
|
||||
.SH "SYNOPSIS"
|
||||
\fBxxhsum [<OPTION>] \.\.\. [<FILE>] \.\.\.\fR
|
||||
.
|
||||
.br
|
||||
\fBxxhsum \-b [<OPTION>] \.\.\.\fR
|
||||
.
|
||||
.P
|
||||
\fBxxh32sum\fR is equivalent to \fBxxhsum \-H0\fR
|
||||
.
|
||||
.br
|
||||
\fBxxh64sum\fR is equivalent to \fBxxhsum \-H1\fR
|
||||
.
|
||||
.SH "DESCRIPTION"
|
||||
Print or check xxHash (32 or 64bit) checksums\. When \fIFILE\fR is \fB\-\fR, read standard input\.
|
||||
.
|
||||
.P
|
||||
\fBxxhsum\fR supports a command line syntax similar but not identical to md5sum(1)\. Differences are: \fBxxhsum\fR doesn\'t have text/binary mode switch (\fB\-b\fR, \fB\-t\fR); \fBxxhsum\fR always treats file as binary file; \fBxxhsum\fR has hash bit width switch (\fB\-H\fR);
|
||||
.
|
||||
.P
|
||||
As xxHash is a fast non\-cryptographic checksum algorithm, \fBxxhsum\fR should not be used for security related purposes\.
|
||||
.
|
||||
.P
|
||||
\fBxxhsum \-b\fR invokes benchmark mode\. See \fIOPTIONS\fR and \fIEXAMPLES\fR for details\.
|
||||
.
|
||||
.SH "OPTIONS"
|
||||
.
|
||||
.TP
|
||||
\fB\-V\fR, \fB\-\-version\fR
|
||||
Display xxhsum version
|
||||
.
|
||||
.TP
|
||||
\fB\-H\fR\fIHASHTYPE\fR
|
||||
Hash selection\. \fIHASHTYPE\fR means \fB0\fR=32bits, \fB1\fR=64bits\. Default value is \fB1\fR (64bits)
|
||||
.
|
||||
.TP
|
||||
\fB\-\-little\-endian\fR
|
||||
Set output hexadecimal checksum value as little endian convention\. By default, value is displayed as big endian\.
|
||||
.
|
||||
.TP
|
||||
\fB\-h\fR, \fB\-\-help\fR
|
||||
Display help and exit
|
||||
.
|
||||
.P
|
||||
\fBThe following four options are useful only when verifying checksums (\fB\-c\fR)\fR
|
||||
.
|
||||
.TP
|
||||
\fB\-c\fR, \fB\-\-check\fR
|
||||
Read xxHash sums from the \fIFILE\fRs and check them
|
||||
.
|
||||
.TP
|
||||
\fB\-\-quiet\fR
|
||||
Exit non\-zero for improperly formatted checksum lines
|
||||
.
|
||||
.TP
|
||||
\fB\-\-strict\fR
|
||||
Don\'t print OK for each successfully verified file
|
||||
.
|
||||
.TP
|
||||
\fB\-\-status\fR
|
||||
Don\'t output anything, status code shows success
|
||||
.
|
||||
.TP
|
||||
\fB\-w\fR, \fB\-\-warn\fR
|
||||
Warn about improperly formatted checksum lines
|
||||
.
|
||||
.P
|
||||
\fBThe following options are useful only benchmark purpose\fR
|
||||
.
|
||||
.TP
|
||||
\fB\-b\fR
|
||||
Benchmark mode\. See \fIEXAMPLES\fR for details\.
|
||||
.
|
||||
.TP
|
||||
\fB\-B\fR\fIBLOCKSIZE\fR
|
||||
Only useful for benchmark mode (\fB\-b\fR)\. See \fIEXAMPLES\fR for details\. \fIBLOCKSIZE\fR specifies benchmark mode\'s test data block size in bytes\. Default value is 102400
|
||||
.
|
||||
.TP
|
||||
\fB\-i\fR\fIITERATIONS\fR
|
||||
Only useful for benchmark mode (\fB\-b\fR)\. See \fIEXAMPLES\fR for details\. \fIITERATIONS\fR specifies number of iterations in benchmark\. Single iteration takes at least 2500 milliseconds\. Default value is 3
|
||||
.
|
||||
.SH "EXIT STATUS"
|
||||
\fBxxhsum\fR exit \fB0\fR on success, \fB1\fR if at least one file couldn\'t be read or doesn\'t have the same checksum as the \fB\-c\fR option\.
|
||||
.
|
||||
.SH "EXAMPLES"
|
||||
Output xxHash (64bit) checksum values of specific files to standard output
|
||||
.
|
||||
.IP "" 4
|
||||
.
|
||||
.nf
|
||||
|
||||
$ xxhsum \-H1 foo bar baz
|
||||
.
|
||||
.fi
|
||||
.
|
||||
.IP "" 0
|
||||
.
|
||||
.P
|
||||
Output xxHash (32bit and 64bit) checksum values of specific files to standard output, and redirect it to \fBxyz\.xxh32\fR and \fBqux\.xxh64\fR
|
||||
.
|
||||
.IP "" 4
|
||||
.
|
||||
.nf
|
||||
|
||||
$ xxhsum \-H0 foo bar baz > xyz\.xxh32
|
||||
$ xxhsum \-H1 foo bar baz > qux\.xxh64
|
||||
.
|
||||
.fi
|
||||
.
|
||||
.IP "" 0
|
||||
.
|
||||
.P
|
||||
Read xxHash sums from specific files and check them
|
||||
.
|
||||
.IP "" 4
|
||||
.
|
||||
.nf
|
||||
|
||||
$ xxhsum \-c xyz\.xxh32 qux\.xxh64
|
||||
.
|
||||
.fi
|
||||
.
|
||||
.IP "" 0
|
||||
.
|
||||
.P
|
||||
Benchmark xxHash algorithm for 16384 bytes data in 10 times\. \fBxxhsum\fR benchmarks xxHash algorithm for 32\-bit and 64\-bit and output results to standard output\. First column means algorithm, second column is source data size in bytes, last column means hash generation speed in mega\-bytes per seconds\.
|
||||
.
|
||||
.IP "" 4
|
||||
.
|
||||
.nf
|
||||
|
||||
$ xxhsum \-b \-i10 \-B16384
|
||||
.
|
||||
.fi
|
||||
.
|
||||
.IP "" 0
|
||||
.
|
||||
.SH "BUGS"
|
||||
Report bugs at: https://github\.com/Cyan4973/xxHash/issues/
|
||||
.
|
||||
.SH "AUTHOR"
|
||||
Yann Collet
|
||||
.
|
||||
.SH "SEE ALSO"
|
||||
md5sum(1)
|
||||
|
|
@ -0,0 +1,124 @@
|
|||
xxhsum(1) -- print or check xxHash non-cryptographic checksums
|
||||
==============================================================
|
||||
|
||||
SYNOPSIS
|
||||
--------
|
||||
|
||||
`xxhsum [<OPTION>] ... [<FILE>] ...`
|
||||
`xxhsum -b [<OPTION>] ...`
|
||||
|
||||
`xxh32sum` is equivalent to `xxhsum -H0`
|
||||
`xxh64sum` is equivalent to `xxhsum -H1`
|
||||
|
||||
|
||||
DESCRIPTION
|
||||
-----------
|
||||
|
||||
Print or check xxHash (32 or 64bit) checksums. When <FILE> is `-`, read
|
||||
standard input.
|
||||
|
||||
`xxhsum` supports a command line syntax similar but not identical to
|
||||
md5sum(1). Differences are:
|
||||
`xxhsum` doesn't have text/binary mode switch (`-b`, `-t`);
|
||||
`xxhsum` always treats file as binary file;
|
||||
`xxhsum` has hash bit width switch (`-H`);
|
||||
|
||||
As xxHash is a fast non-cryptographic checksum algorithm,
|
||||
`xxhsum` should not be used for security related purposes.
|
||||
|
||||
`xxhsum -b` invokes benchmark mode. See [OPTIONS](#OPTIONS) and [EXAMPLES](#EXAMPLES) for details.
|
||||
|
||||
OPTIONS
|
||||
-------
|
||||
|
||||
* `-V`, `--version`:
|
||||
Display xxhsum version
|
||||
|
||||
* `-H`<HASHTYPE>:
|
||||
Hash selection. <HASHTYPE> means `0`=32bits, `1`=64bits.
|
||||
Default value is `1` (64bits)
|
||||
|
||||
* `--little-endian`:
|
||||
Set output hexadecimal checksum value as little endian convention.
|
||||
By default, value is displayed as big endian.
|
||||
|
||||
* `-h`, `--help`:
|
||||
Display help and exit
|
||||
|
||||
**The following four options are useful only when verifying checksums (`-c`)**
|
||||
|
||||
* `-c`, `--check`:
|
||||
Read xxHash sums from the <FILE>s and check them
|
||||
|
||||
* `--quiet`:
|
||||
Exit non-zero for improperly formatted checksum lines
|
||||
|
||||
* `--strict`:
|
||||
Don't print OK for each successfully verified file
|
||||
|
||||
* `--status`:
|
||||
Don't output anything, status code shows success
|
||||
|
||||
* `-w`, `--warn`:
|
||||
Warn about improperly formatted checksum lines
|
||||
|
||||
**The following options are useful only benchmark purpose**
|
||||
|
||||
* `-b`:
|
||||
Benchmark mode. See [EXAMPLES](#EXAMPLES) for details.
|
||||
|
||||
* `-B`<BLOCKSIZE>:
|
||||
Only useful for benchmark mode (`-b`). See [EXAMPLES](#EXAMPLES) for details.
|
||||
<BLOCKSIZE> specifies benchmark mode's test data block size in bytes.
|
||||
Default value is 102400
|
||||
|
||||
* `-i`<ITERATIONS>:
|
||||
Only useful for benchmark mode (`-b`). See [EXAMPLES](#EXAMPLES) for details.
|
||||
<ITERATIONS> specifies number of iterations in benchmark. Single iteration
|
||||
takes at least 2500 milliseconds. Default value is 3
|
||||
|
||||
EXIT STATUS
|
||||
-----------
|
||||
|
||||
`xxhsum` exit `0` on success, `1` if at least one file couldn't be read or
|
||||
doesn't have the same checksum as the `-c` option.
|
||||
|
||||
EXAMPLES
|
||||
--------
|
||||
|
||||
Output xxHash (64bit) checksum values of specific files to standard output
|
||||
|
||||
$ xxhsum -H1 foo bar baz
|
||||
|
||||
Output xxHash (32bit and 64bit) checksum values of specific files to standard
|
||||
output, and redirect it to `xyz.xxh32` and `qux.xxh64`
|
||||
|
||||
$ xxhsum -H0 foo bar baz > xyz.xxh32
|
||||
$ xxhsum -H1 foo bar baz > qux.xxh64
|
||||
|
||||
Read xxHash sums from specific files and check them
|
||||
|
||||
$ xxhsum -c xyz.xxh32 qux.xxh64
|
||||
|
||||
Benchmark xxHash algorithm for 16384 bytes data in 10 times. `xxhsum`
|
||||
benchmarks xxHash algorithm for 32-bit and 64-bit and output results to
|
||||
standard output. First column means algorithm, second column is source data
|
||||
size in bytes, last column means hash generation speed in mega-bytes per
|
||||
seconds.
|
||||
|
||||
$ xxhsum -b -i10 -B16384
|
||||
|
||||
BUGS
|
||||
----
|
||||
|
||||
Report bugs at: https://github.com/Cyan4973/xxHash/issues/
|
||||
|
||||
AUTHOR
|
||||
------
|
||||
|
||||
Yann Collet
|
||||
|
||||
SEE ALSO
|
||||
--------
|
||||
|
||||
md5sum(1)
|
||||
File diff suppressed because it is too large
Load Diff
|
|
@ -12,7 +12,7 @@
|
|||
#include <time.h>
|
||||
|
||||
#include <zlib.h>
|
||||
#include "deps/xxhash/xxhash.h"
|
||||
#include <xxhash.h>
|
||||
|
||||
#define LOGJVS(...) DEBUG_LOG(JVS, __VA_ARGS__)
|
||||
|
||||
|
|
|
|||
|
|
@ -10,7 +10,7 @@
|
|||
#include "hw/mem/vmem32.h"
|
||||
#include "hw/sh4/modules/mmu.h"
|
||||
#include "deps/xbrz/xbrz.h"
|
||||
#include "deps/xxhash/xxhash.h"
|
||||
#include <xxhash.h>
|
||||
|
||||
u8* vq_codebook;
|
||||
u32 palette_index;
|
||||
|
|
|
|||
|
|
@ -3,7 +3,7 @@
|
|||
#include "rend/TexCache.h"
|
||||
#include "hw/pvr/pvr_mem.h"
|
||||
#include "hw/mem/_vmem.h"
|
||||
#include "deps/xxhash/xxhash.h"
|
||||
#include <xxhash.h>
|
||||
#include "CustomTexture.h"
|
||||
|
||||
#include <png.h>
|
||||
|
|
|
|||
|
|
@ -207,7 +207,6 @@
|
|||
AE43537322C9420C005E19CE /* ConsoleListenerNix.cpp in Sources */ = {isa = PBXBuildFile; fileRef = AE43536C22C9420C005E19CE /* ConsoleListenerNix.cpp */; };
|
||||
AE43537422C9420C005E19CE /* ConsoleListenerWin.cpp in Sources */ = {isa = PBXBuildFile; fileRef = AE43536D22C9420C005E19CE /* ConsoleListenerWin.cpp */; };
|
||||
AE43537522C9420C005E19CE /* LogManager.cpp in Sources */ = {isa = PBXBuildFile; fileRef = AE43536F22C9420C005E19CE /* LogManager.cpp */; };
|
||||
AE649BB62188689000EF4A81 /* xxhash.c in Sources */ = {isa = PBXBuildFile; fileRef = AE649BB42188689000EF4A81 /* xxhash.c */; };
|
||||
AE649BF3218C552500EF4A81 /* bitmath.c in Sources */ = {isa = PBXBuildFile; fileRef = AE649BCD218C552500EF4A81 /* bitmath.c */; };
|
||||
AE649BF4218C552500EF4A81 /* bitreader.c in Sources */ = {isa = PBXBuildFile; fileRef = AE649BCE218C552500EF4A81 /* bitreader.c */; };
|
||||
AE649BF5218C552500EF4A81 /* cpu.c in Sources */ = {isa = PBXBuildFile; fileRef = AE649BCF218C552500EF4A81 /* cpu.c */; };
|
||||
|
|
@ -688,8 +687,6 @@
|
|||
AE43537122C9420C005E19CE /* StringUtil.h */ = {isa = PBXFileReference; fileEncoding = 4; lastKnownFileType = sourcecode.c.h; path = StringUtil.h; sourceTree = "<group>"; };
|
||||
AE60BD9F22256E2500FA8A5B /* osx_keyboard.h */ = {isa = PBXFileReference; lastKnownFileType = sourcecode.c.h; path = osx_keyboard.h; sourceTree = "<group>"; };
|
||||
AE60BDA02225725800FA8A5B /* osx_gamepad.h */ = {isa = PBXFileReference; lastKnownFileType = sourcecode.c.h; path = osx_gamepad.h; sourceTree = "<group>"; };
|
||||
AE649BB42188689000EF4A81 /* xxhash.c */ = {isa = PBXFileReference; fileEncoding = 4; lastKnownFileType = sourcecode.c.c; path = xxhash.c; sourceTree = "<group>"; };
|
||||
AE649BB52188689000EF4A81 /* xxhash.h */ = {isa = PBXFileReference; fileEncoding = 4; lastKnownFileType = sourcecode.c.h; path = xxhash.h; sourceTree = "<group>"; };
|
||||
AE649BBA218C552500EF4A81 /* all.h */ = {isa = PBXFileReference; fileEncoding = 4; lastKnownFileType = sourcecode.c.h; path = all.h; sourceTree = "<group>"; };
|
||||
AE649BBB218C552500EF4A81 /* assert.h */ = {isa = PBXFileReference; fileEncoding = 4; lastKnownFileType = sourcecode.c.h; path = assert.h; sourceTree = "<group>"; };
|
||||
AE649BBC218C552500EF4A81 /* callback.h */ = {isa = PBXFileReference; fileEncoding = 4; lastKnownFileType = sourcecode.c.h; path = callback.h; sourceTree = "<group>"; };
|
||||
|
|
@ -1073,7 +1070,6 @@
|
|||
AEFF7ECE214D9D580068CE11 /* picotcp */,
|
||||
AE8C273A21122E2500D4D8F4 /* xbrz */,
|
||||
AE1E292620947D4700FC6BA2 /* xbyak */,
|
||||
AE649BB32188689000EF4A81 /* xxhash */,
|
||||
84B7BDA01B72720100F9733F /* zlib */,
|
||||
);
|
||||
name = deps;
|
||||
|
|
@ -1754,15 +1750,6 @@
|
|||
path = ../../../core/log;
|
||||
sourceTree = "<group>";
|
||||
};
|
||||
AE649BB32188689000EF4A81 /* xxhash */ = {
|
||||
isa = PBXGroup;
|
||||
children = (
|
||||
AE649BB42188689000EF4A81 /* xxhash.c */,
|
||||
AE649BB52188689000EF4A81 /* xxhash.h */,
|
||||
);
|
||||
path = xxhash;
|
||||
sourceTree = "<group>";
|
||||
};
|
||||
AE649BB7218C552500EF4A81 /* flac */ = {
|
||||
isa = PBXGroup;
|
||||
children = (
|
||||
|
|
@ -2528,7 +2515,6 @@
|
|||
84B7BF661B72720200F9733F /* nullDC.cpp in Sources */,
|
||||
AEE6279422247C0A00EC7E89 /* gui_util.cpp in Sources */,
|
||||
84B7BF291B72720200F9733F /* sgc_if.cpp in Sources */,
|
||||
AE649BB62188689000EF4A81 /* xxhash.c in Sources */,
|
||||
84B7BF5E1B72720200F9733F /* ImgReader.cpp in Sources */,
|
||||
84B7BEB51B72720200F9733F /* sha1.cpp in Sources */,
|
||||
84B7BF2C1B72720200F9733F /* vbaARM.cpp in Sources */,
|
||||
|
|
@ -2632,6 +2618,7 @@
|
|||
CHD5_FLAC,
|
||||
"HAVE_CONFIG_H=1",
|
||||
"USE_SDL=1",
|
||||
XXH_INLINE_ALL,
|
||||
);
|
||||
GCC_SYMBOLS_PRIVATE_EXTERN = NO;
|
||||
GCC_WARN_64_TO_32_BIT_CONVERSION = YES;
|
||||
|
|
@ -2685,6 +2672,7 @@
|
|||
"HAVE_CONFIG_H=1",
|
||||
RELEASE,
|
||||
"USE_SDL=1",
|
||||
XXH_INLINE_ALL,
|
||||
);
|
||||
GCC_WARN_64_TO_32_BIT_CONVERSION = YES;
|
||||
GCC_WARN_ABOUT_RETURN_TYPE = YES_ERROR;
|
||||
|
|
@ -2726,6 +2714,7 @@
|
|||
../../../core/deps/flac/include,
|
||||
../../../core/deps/flac/src/libFLAC/include,
|
||||
../../../core/deps/libpng,
|
||||
../../../core/deps/xxhash,
|
||||
../../../core/deps/zlib,
|
||||
/usr/local/include,
|
||||
);
|
||||
|
|
@ -2768,6 +2757,7 @@
|
|||
../../../core/deps/flac/include,
|
||||
../../../core/deps/flac/src/libFLAC/include,
|
||||
../../../core/deps/libpng,
|
||||
../../../core/deps/xxhash,
|
||||
../../../core/deps/zlib,
|
||||
/usr/local/include,
|
||||
);
|
||||
|
|
@ -2859,6 +2849,7 @@
|
|||
_7ZIP_ST,
|
||||
CHD5_FLAC,
|
||||
"HAVE_CONFIG_H=1",
|
||||
XXH_INLINE_ALL,
|
||||
"${CFLAGS}",
|
||||
);
|
||||
GCC_SYMBOLS_PRIVATE_EXTERN = NO;
|
||||
|
|
@ -2904,6 +2895,7 @@
|
|||
../../../core/deps/flac/include,
|
||||
../../../core/deps/flac/src/libFLAC/include,
|
||||
../../../core/deps/libpng,
|
||||
../../../core/deps/xxhash,
|
||||
../../../core/deps/zlib,
|
||||
/usr/local/include,
|
||||
);
|
||||
|
|
@ -2979,6 +2971,7 @@
|
|||
CHD5_FLAC,
|
||||
"HAVE_CONFIG_H=1",
|
||||
RELEASE,
|
||||
XXH_INLINE_ALL,
|
||||
"${CFLAGS}",
|
||||
);
|
||||
GCC_WARN_64_TO_32_BIT_CONVERSION = YES;
|
||||
|
|
@ -3018,6 +3011,7 @@
|
|||
../../../core/deps/flac/include,
|
||||
../../../core/deps/flac/src/libFLAC/include,
|
||||
../../../core/deps/libpng,
|
||||
../../../core/deps/xxhash,
|
||||
../../../core/deps/zlib,
|
||||
/usr/local/include,
|
||||
);
|
||||
|
|
|
|||
Loading…
Reference in New Issue